
被 Claude Fable 5 推向台前的概念:安全护栏
作者:望宸
Anthropic 发布了 Claude Fable 5,比跑分更值得拆解的是它的运行时行为,当某些请求触发了安全边界,用户的请求将会被切换到 Opus4.8。
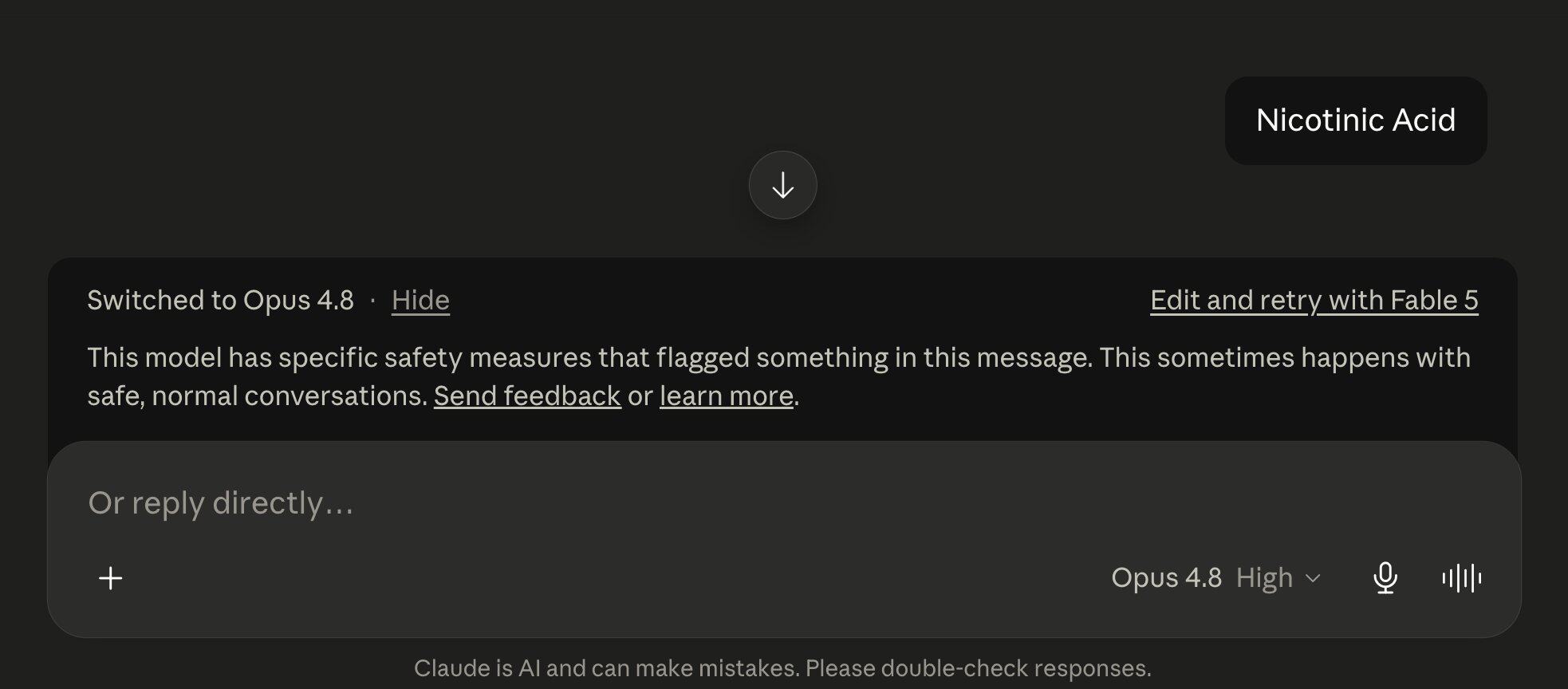
X用户@amarjeet 的测试
Claude 告诉你:我被护栏拦下了,换了一个备用模型给你回答。
这是一个巧妙的用户体验设计。在此之前,护栏是后端的事。用户发送一条消息、收到一条回复,中间发生了什么,有没有被检查、有没有被降级、有没有被另一个模型接管,用户是不知道的,整个过程对用户来说是一个黑盒。
Fable 5 把盒子打开了一条缝。护栏从隐形的基础设施,变成了产品体验的一部分。
但对做技术团队来说,安全护栏不是一个全新的概念。如果你在阿里云 AI 网关上配置过 AI 安全防护策略,你对护栏一定很熟悉,他能保障模型内容输出的安全性。
无独有偶,云计算将安全护栏用于资源的约束,AI 网关将安全护栏用于约束模型的输出,Anthropic 则将安全护栏用于约束两个模型之间的路由。约束对象在变化,但设计思路是一脉相承的。本文以安全护栏为主线,厘清其在以上主流场景的功能定位和实现原理。
一、云平台的安全护栏:约束资源
多人操作同一个云账户体系,如何确保没人在错误的地方创建资源、没人开放不该开放的端口。这里的约束对象是资源,包括 ECS 实例、RDS 数据库、OSS 存储桶、VPC 网络配置等。护栏的职责是给资源的创建、变更和访问建立鉴权机制,越线的操作当场被拒绝,而不是等出了事再审计追责。
阿里云在资源约束上构建了一套分层的策略体系,从上到下形成逐级收紧的控制结构。
最上层是资源目录的管控策略(SCP)。SCP 作用在组织级别,对子账号和资源夹的可执行操作设定上界。举个例子:某产品团队的自动化脚本试图在新加坡 Region 创建 ECS 实例,但企业安全团队在资源目录中早已设置了管控策略,禁止子账号开通海外 Region 的任何资源。API 直接返回权限拒绝,不需要审批流程介入,管控策略 7×24 在线。
再下一层是 RAM 权限策略。一段 JSON 声明谁能对什么资源做什么操作,Action、Resource、Effect 三元组,最小权限原则的标准实现。归纳一下云平台护栏的特征:策略以数据形式声明,执行在旁路独立进行,每次拒绝都产生可审计的记录。这三个特征在后面两个场景中会反复出现。
二、AI 网关的安全护栏:约束内容输出
当约束对象从”资源”变成”模型输出”,问题的性质发生了变化。资源约束是确定性的,一个 API 调用要么有权限要么没有。模型输出约束是概率性的,同一个 prompt,模型有可能生成合规内容,也有可能生成违规内容。而且模型在逐词生成回复的过程中,前几个词可能是安全的,后面突然滑向风险区域。
阿里云 AI 网关上提供的 AI 安全护栏就是为了解决这个问题。打开阿里云 AI 网关控制台,进入 Model API,就能开启 AI 安全防护功能,用于内容合规检测、敏感内容检测、提示词攻击检测等常场景。
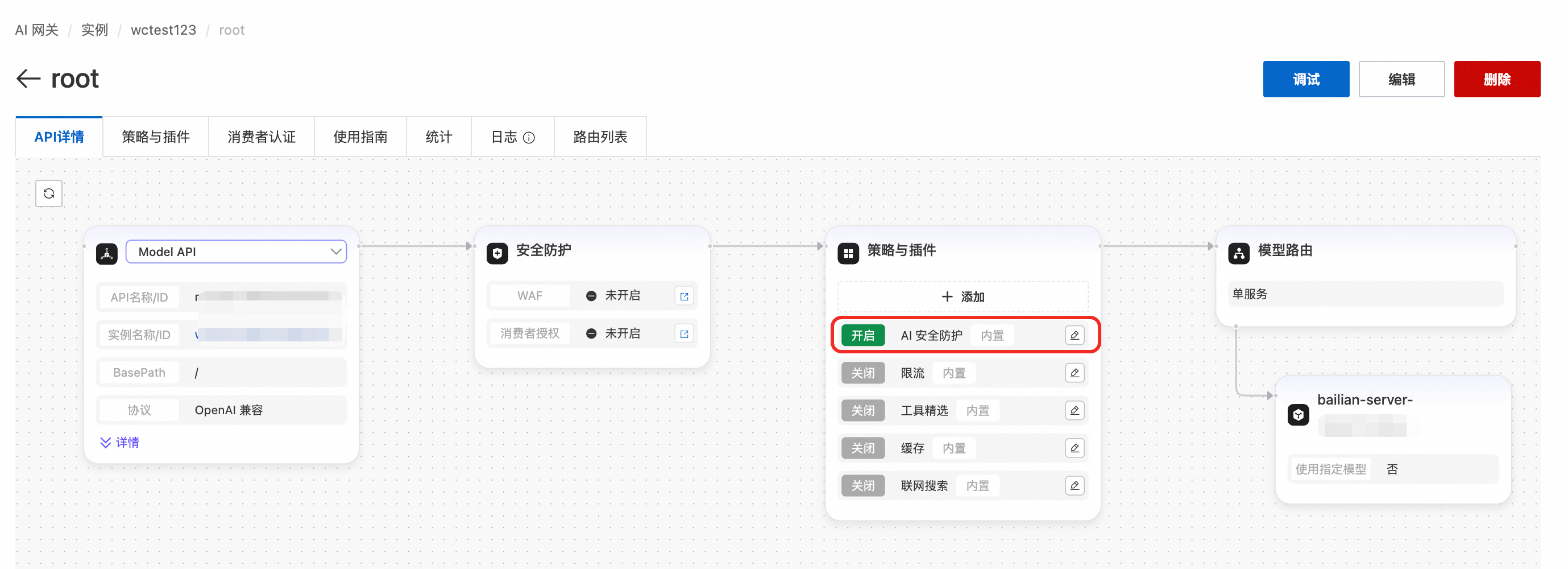
阿里云 AI 网关配置 Model API 的界面
AI 安全护栏的检测引擎底座是 Qwen3Guard,通义千问家族中首款专为安全分类设计的护栏模型。它有两个版本,应对两种不同的场景。
- Qwen3Guard-Gen 是生成式版本:对完整的用户输入或模型输出做一次性安全分类。适用于离线数据清洗、训练语料去毒、以及作为强化学习中的安全奖励信号。
- Qwen3Guard-Stream 是流式版本:在 Transformer 模型的最后一层附加了两个轻量级分类头,使模型能够逐词接收正在生成的回复,并在每一个 token 输出时即时给出安全判定。用户每看到一个字,这个字就已经被检查过了。
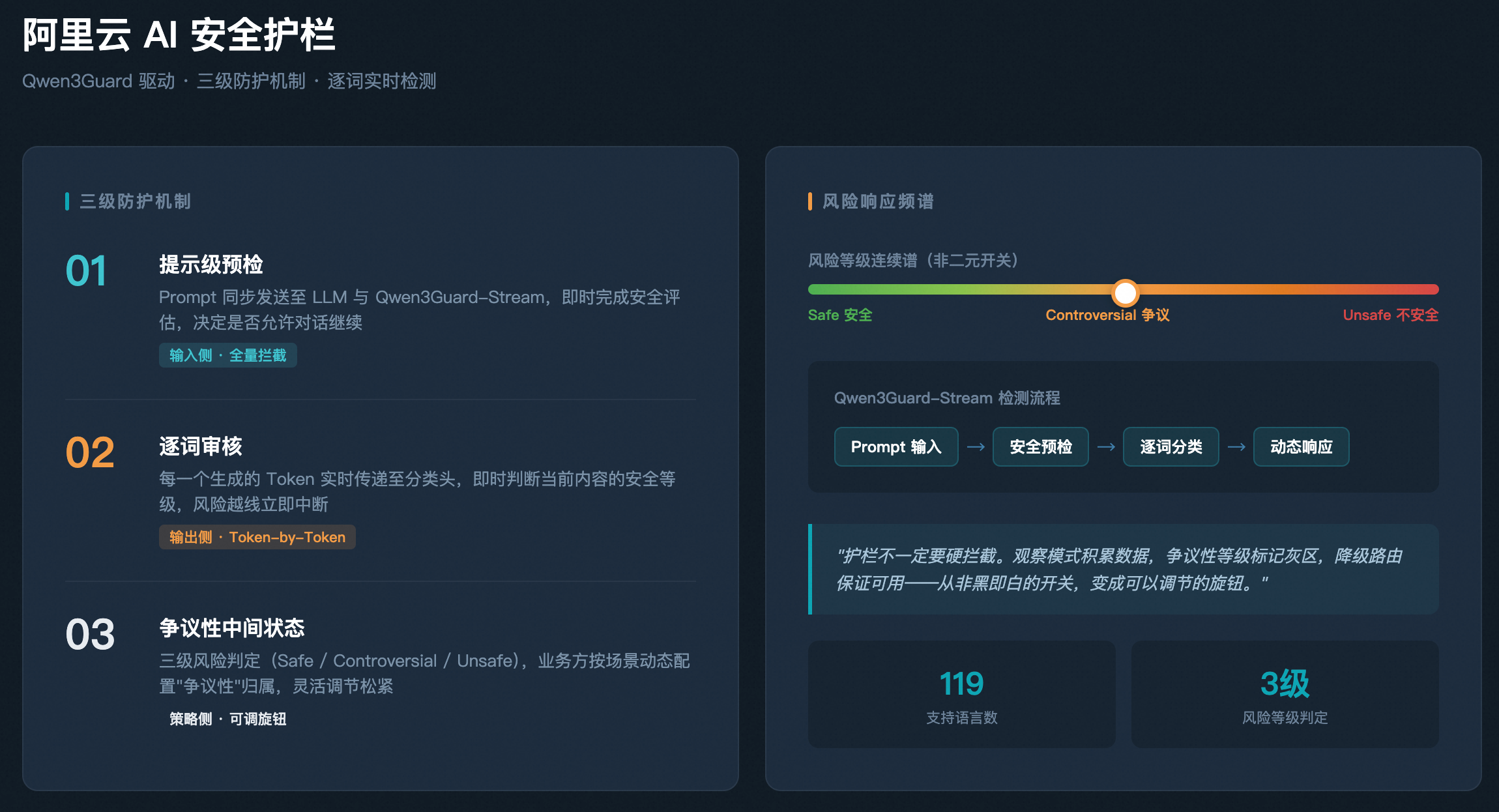
工作流程分两步:
- 第一步:提示级预检,用户输入的 prompt 同步发送给大模型和 Qwen3Guard-Stream,后者立即对 prompt 做安全评估,决定是否允许对话继续。
- 第二步:逐词审核,如果对话获准继续,LLM 每生成一个 token 都实时传递给 Qwen3Guard-Stream,由其即时判断当前内容的安全等级。一旦风险等级越过阈值,可以立即中断生成,而不是等到整条回复输出完毕。
此外,Qwen3Guard 新增了”争议性”这一中间状态。用户可以根据业务场景动态决定”争议性”内容归入安全还是不安全。对内容创作平台可以放宽,对未成年人教育产品需要收紧。同一个引擎,不同的阈值配置,适配不同的业务要求。这种留有余地的设计,让护栏从一个非黑即白的开关变成了一个可以调节的按钮。这和后面 Fable 5 的降级路由策略,本质上是同一种思路。
三、Anthropic 的安全护栏:约束模型间路由
前两个场景的护栏,约束对象都相对直观,资源的创建权限、模型输出的内容合规。Anthropic 在 Fable 5 约束的是两个模型之间的路由决策。
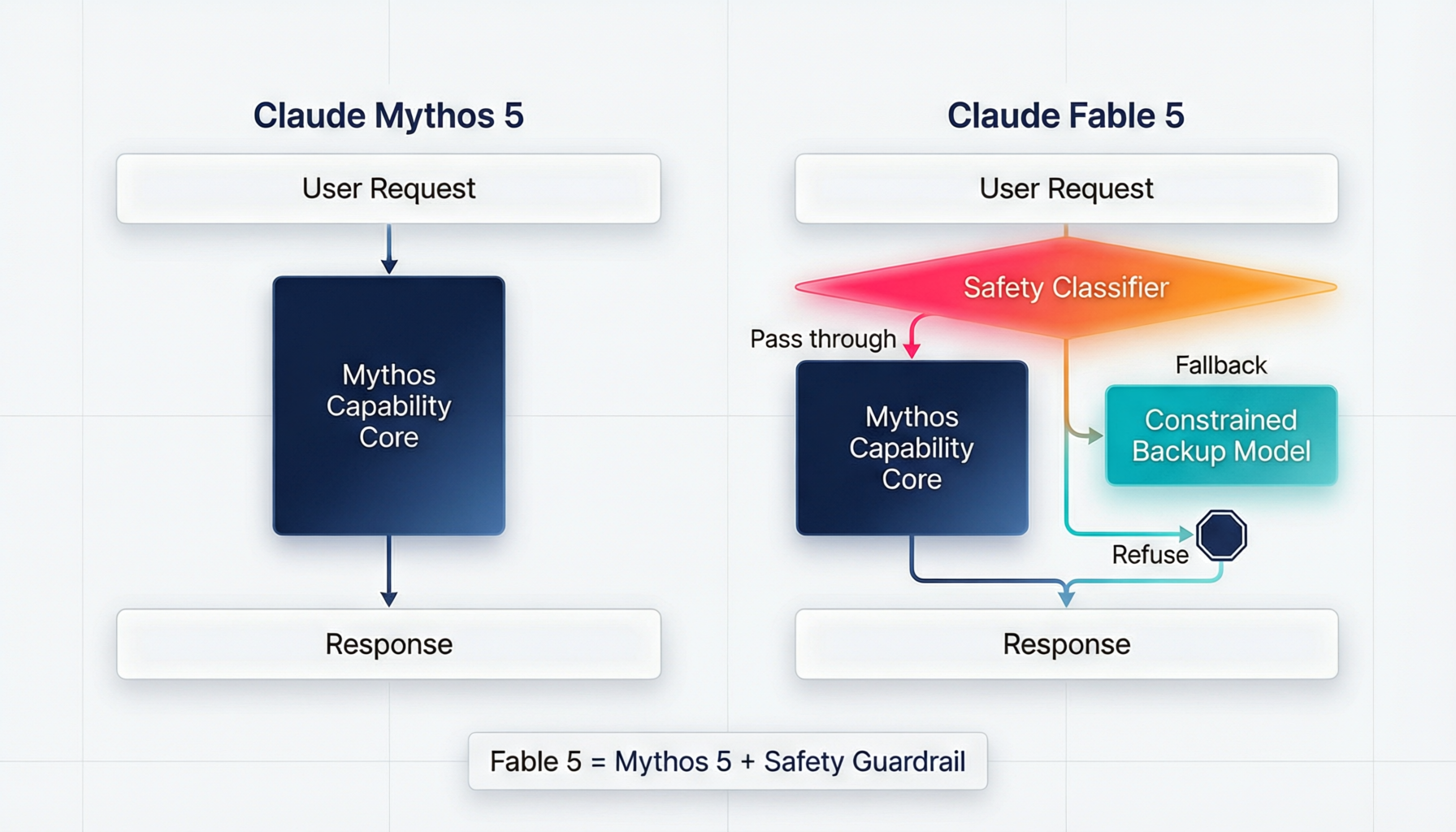
Fable 5 底层是 Mythos 模型,在网络安全、生物化学等领域具备极强能力。这些能力不应该无条件释放给所有用户。但与此同时,Anthropic 也不想对用户简单说一句”Sorry, I can’t help with that”。那是一种很差的产品体验。
它的解法是:在 Fable 5 前面架一道路由护栏。触发时不拒绝,而是自动将请求路由到能力稍弱但更安全的 Opus 4.8 来回答。用户仍然得到有价值的回复,只是能力有所收窄。同时系统明确告知用户发生了什么。
Fable 5 的护栏由三个组件构成。
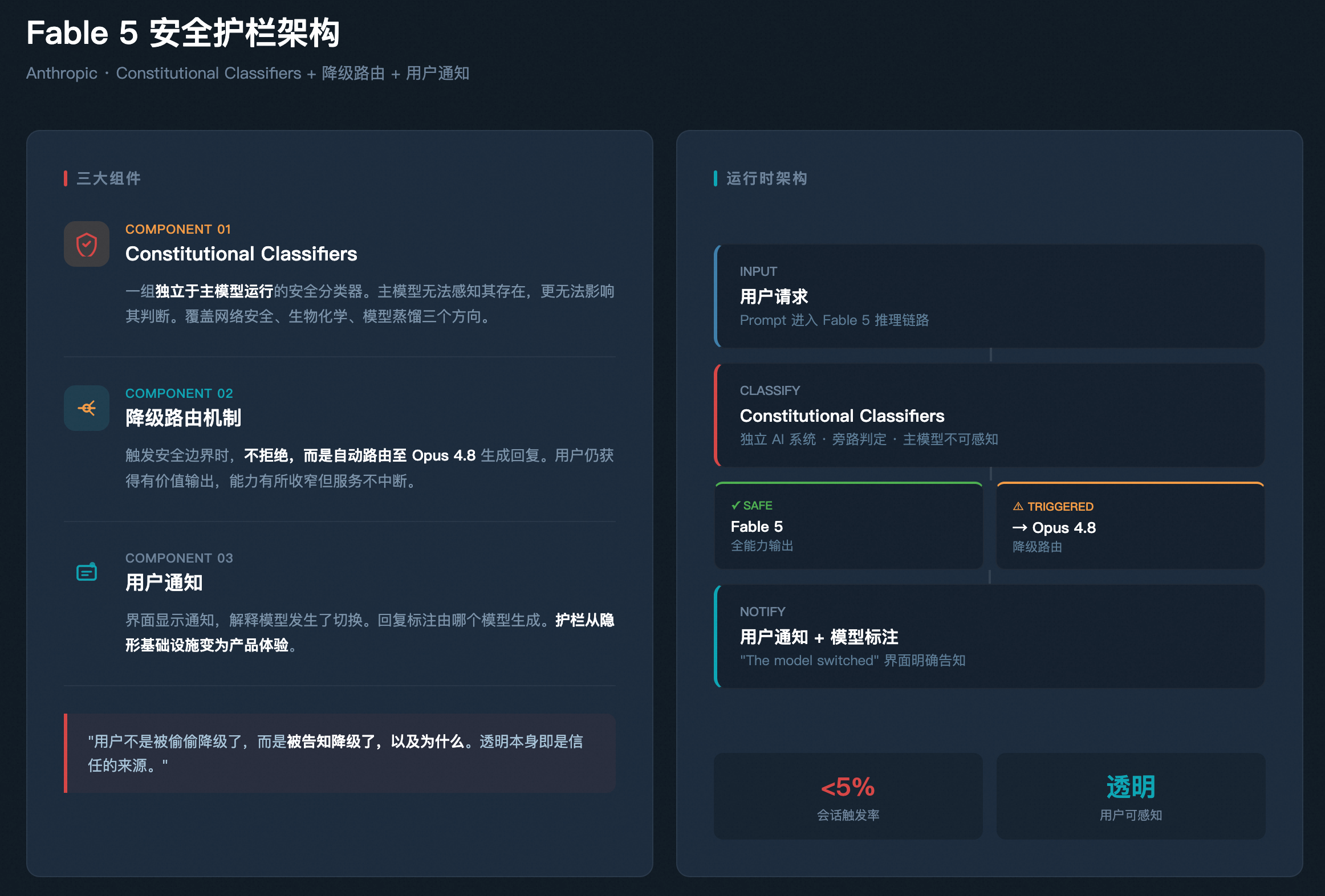
第一个是一组独立于主模型运行的安全分类器。它们是独立的 AI 系统,主模型无法感知它们的存在,更无法影响它们的判断。这一点很关键:如果让模型”自己判断”该不该回答,模型在对抗性场景下是不可靠的,因为用户可以通过 prompt 技巧绕过自律。分类器独立运行,模型绕不过一个它看不见的东西。分类器覆盖三个方向:网络安全能力、生物化学能力、模型知识蒸馏。这三个方向是 Mythos 级别模型最敏感的能力区间。
第二个是降级路由机制。当分类器判定请求触发安全边界,系统自动将回复路由至 Opus 4.8 生成。不是拒绝,是降级。用户仍然拿到回答,系统仍然在工作,只是换了一条路径走。Anthropic 公布的数据是,不到 5% 的会话会触发这一机制。
第三个是用户通知。每次触发降级路由,界面上都会显示一条通知,解释模型发生了切换,回复也会标注由哪个模型生成。这一步把护栏从”后端基础设施”变成了”前端产品体验”。用户不是被偷偷降级了,而是被告知降级了,以及为什么。
此外还有一个弹性机制:Trusted Access Program。经过审核的安全研究者可以申请完整的 Mythos 级能力访问。对他们来说,护栏是打开的。这意味着护栏的松紧度不是固定的,而是根据使用者的信任等级动态调整。
回想阿里云 AI 网关的”按消费者匹配”,重点业务高等级拦截、内部测试采用观察模式。本质上是同一个设计思路:不同调用方享受不同的护栏策略。一刀切的护栏要么误伤太多合法用户,要么漏过太多恶意请求,分级是正确的方向。
四、不同场景下,安全护栏的共性设计策略
约束对象从资源到模型输出,再到模型间路由,场景差异较大,但设计策略上存在着一些共性。

1、声明式而非编程式。
RAM 策略是一段 JSON,AI 安全护栏是控制台上的开关、阈值滑块和过滤词表,Fable 5 的分类器方向由安全团队配置。改护栏不需要改系统代码,安全团队今天发现一个新的风险类型,今天就能加上对应策略,不需要等排期上线。
2、旁路执行而非内嵌自律。
管控策略独立于子账号运行,AI 安全护栏独立于模型运行(Qwen3Guard 是独立的检测引擎,接入的模型无法感知其存在),Fable 5 的分类器独立于主模型运行。被保护的系统看不到护栏,更改不了护栏。内嵌式防护(让模型自己判断)本质上是靠自律,自律在对抗性场景下不可靠。
3、梯度响应而非二元开关。
配置审计可以只记录不修改,AI 安全护栏有观察模式和三级风险等级(安全/争议/不安全),Fable 5 有降级路由。护栏的响应不是非黑即白的”通过/拒绝”,而是一个频谱:放行 → 观察 → 降级 → 确认 → 拒绝。梯度越细,误伤越少。
4、可观测而非静默。
ActionTrail 记录每次权限拒绝,AI 安全护栏将检查结果写入日志并支持日志分析面板,Fable 5 直接在用户界面上通知触发。不可观测的护栏无法被调优。Fable 5 把可观测性推到了极致,连用户本人都能看到护栏对自己的影响。
5、分层继承而非一刀切。
资源目录从 Root → 资源夹 → 成员账号逐层细化。阿里云 AI 安全护栏从全局策略 → 按消费者分组 → 单个消费者逐级匹配,检测阈值精确到 0-100 置信分。Fable 5 从系统级 policy → 全局分类器 → Trusted Access Program 按人放宽。上层定底线,下层做细化,安全性和自由度共存。
安全护栏被被 Claude Fable 5 推向前台,也许会被应用于更加广泛的场景。你平时感受不到它,但当它生效的时候,它会告诉你。这将是护栏最好的状态。