2025 智能体工程现状
望宸
|
2025年12月19日
|
LangChain 近期发布了《State of Agent Engineering》报告,内容比较翔实,全面分析了 AI 智能体在企业中的采用现状、挑战与趋势。(或尚未应用的原因)
我们对报告进行了翻译,并做了些描述和内容排序上的的优化,让中文读者更易于理解。同时,我们将今年9月底发布的《AI 原生应用架构白皮书》中的部分调研数据,和《State of Agent Engineering》进行比对,以了解智能体工程现状在国内外的差异,以及对共性问题提供了些应对思路。
报告和白皮书原文
《State of Agent Engineering》https://www.langchain.com/state-of-agent-engineering
《AI 原生应用架构白皮书》ttps://developer.aliyun.com/ebook/8479
《State of Agent Engineering》人群画像:1340 份有效回复,包括工程师、产品经理、业务负责人和企业高管。
《AI 原生应用架构白皮书》人群画像:来自参加杭州、上海、北京、深圳、广州举办的6场 AI 原生为主题的线下开发者沙龙,填写问卷的总人数是1382人,以架构师、后端、运维、技术负责人为主。
一、什么是智能体工程?
智能体工程是将大语言模型(LLM)转化为可靠系统的迭代过程。由于智能体具有不确定性,我们认为,工程师必须通过快速迭代来持续优化其输出质量。
二、核心发现
企业的关注度不再问是否要构建智能体,而是关注如何可靠、高效且规模化地部署智能体,且这一趋势会一直蔓延到2026年,直到能有效的解决问题。核心发现:
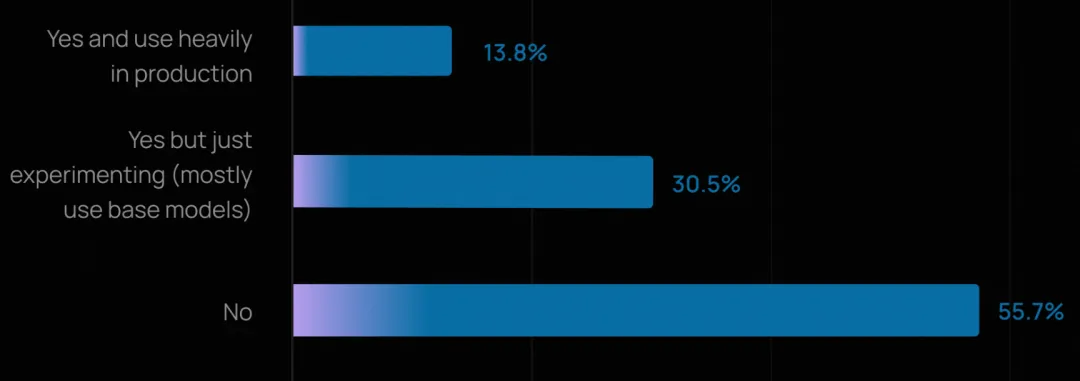
生产落地势头强劲:57% 的受访者已将智能体投入生产环境,大型企业引领采纳潮流。
质量是最大拦路虎:32% 的人将“质量”列为首要障碍;相比之下,成本担忧较去年有所下降。
可观测性已成为标配:近 89% 的受访者为其智能体实施了可观测性方案,远超评估(evals)的采用率(52%)。
多模型策略成常态:OpenAI 的 GPT 系列模型占据主导,但 Gemini、Claude 和开源模型也获得广泛应用;微调尚未普及。
三、大型企业引领采纳浪潮
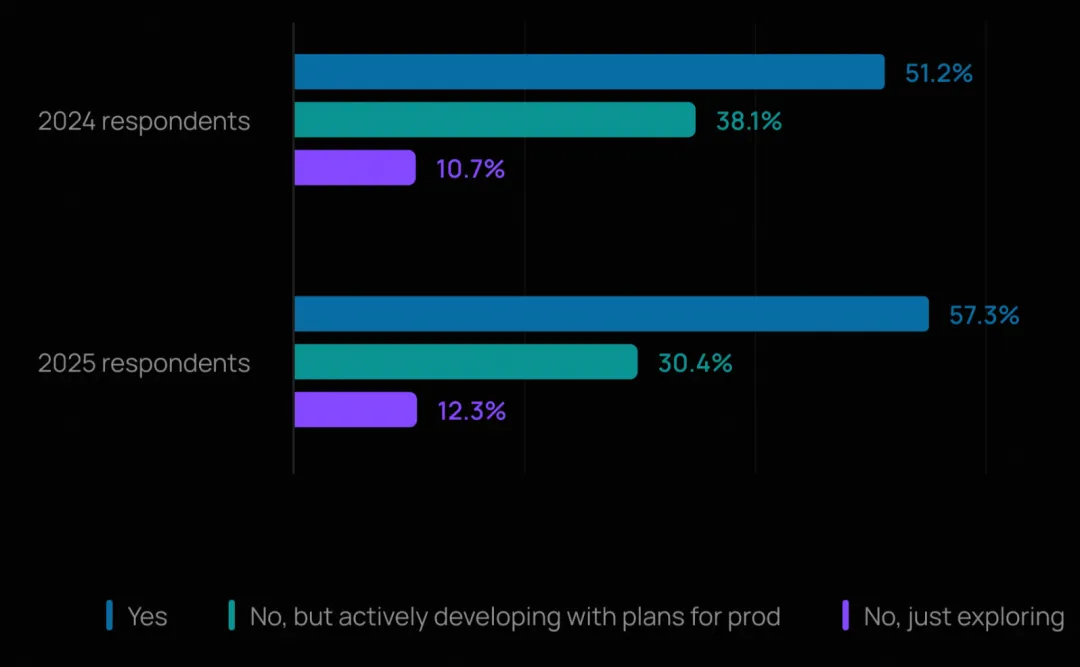
超过半数(57.3%)的受访者表示其公司已在生产环境中运行智能体,另有 30.4% 正在积极开发并有明确的上线计划。
这标志着相较于去年(51% 的受访者称已有智能体上线),有了显著增长。企业正从概念验证阶段迈向生产部署。
《AI 原生应用架构白皮书》中关于实施进程的调研结果,国内外的智能体发展势头均比较强势,企业关注的不再是“是否”要推出智能体,而是“如何”以及“何时”。

四、规模效应显现
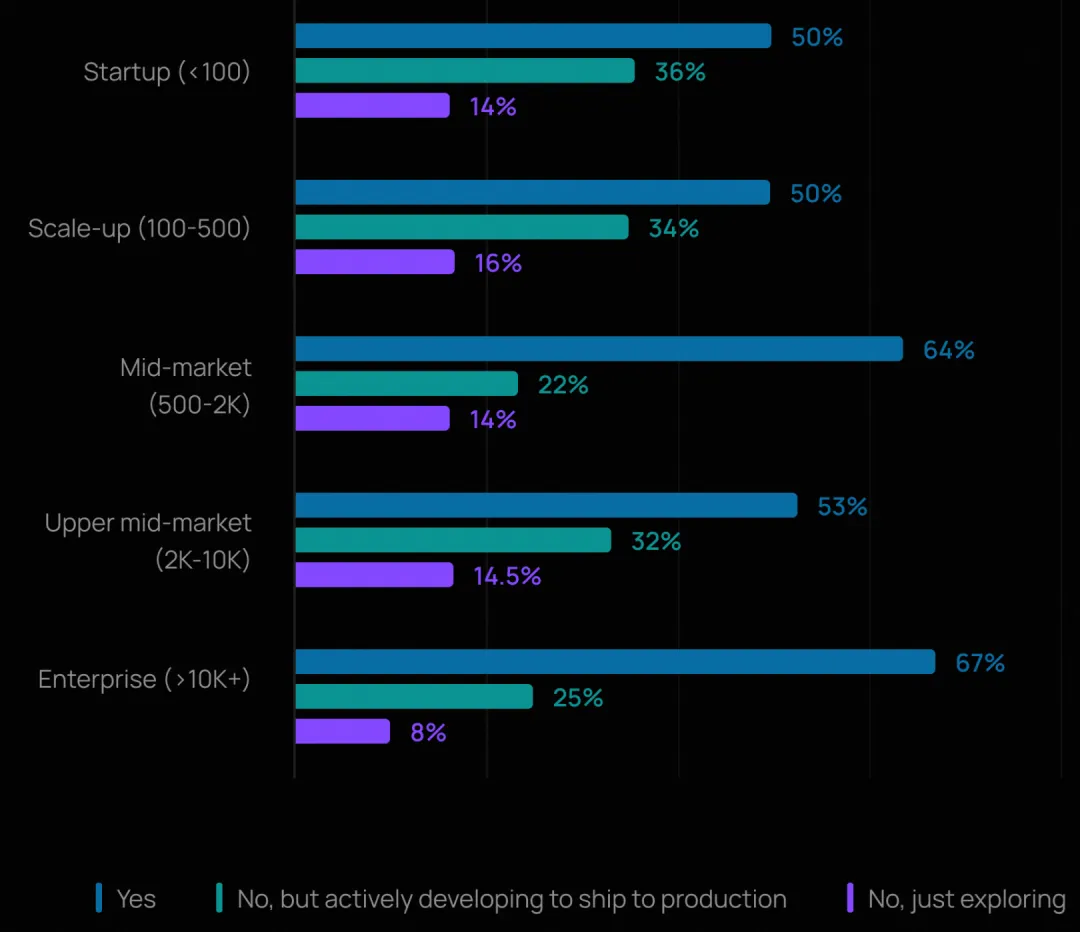
在员工规模超 10,000 人的大型组织中,67% 已部署智能体,24% 正在开发中;而在员工少于 100 人的小型组织中,这一比例分别为 50% 和 36%。这表明大型企业正更快地从试点走向可持续演进,可能得益于其在平台团队、安全性和可靠性基础设施上,有着更大的投入。
五、主流智能体应用场景
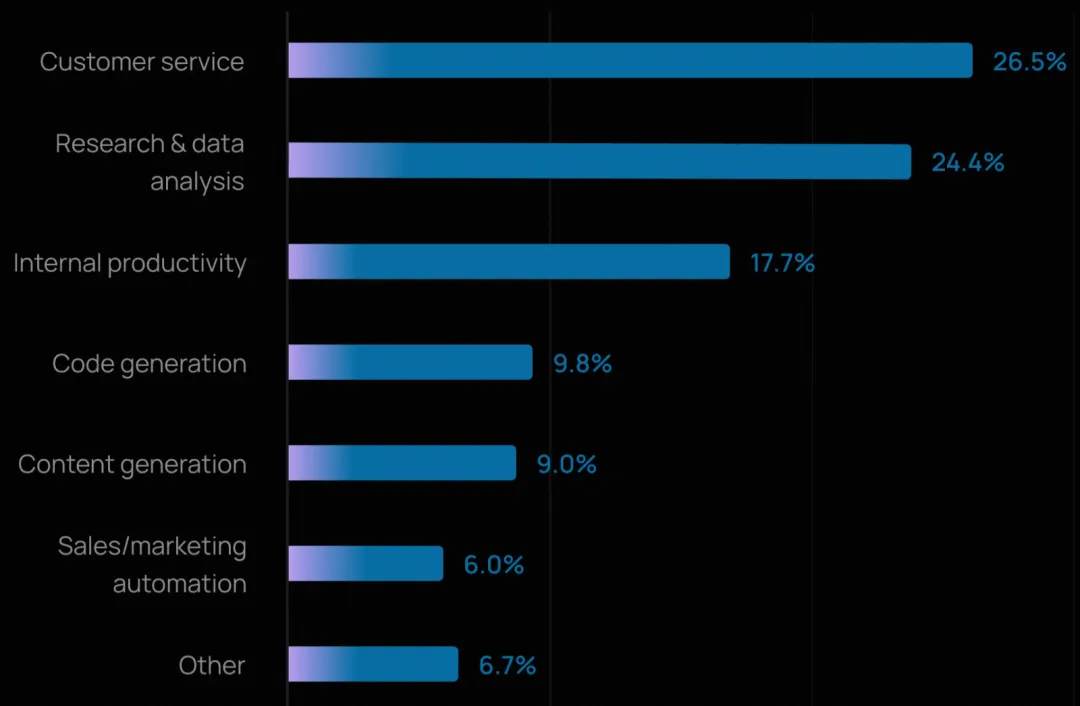
客户服务是最常见的智能体用例(26.5%),紧随其后的是研究与数据分析(24.4%)。这两类应用合计占所有主要部署场景的一半以上。
这一结果表明:
企业正越来越多地将智能体直接面向客户,而不仅限于内部使用。同时,智能体在提升内部效率方面也表现出显著的价值,18% 的受访者提到将其用于内部工作流自动化。
研究与数据分析场景的流行,进一步印证了智能体当前的优势所在,即整合海量信息、跨源推理,并加速知识密集型任务。
今年的受访者选择的应用场景更加分散(每人仅可选一项主要用例),说明智能体的应用正在从早期少数场景向更广泛的领域拓展。
大企业的偏好略有不同,在万人以上企业中,内部生产力提升成为首要用例(26.8%),客户服务(24.7%)和研究与数据分析(22.2%)紧随其后。这表明大型企业可能优先聚焦于提升内部团队效率,再逐步或同步向终端用户部署。
《AI 原生应用架构白皮书》提供了以下4类落地场景供多选,重塑客户互动 > 重塑业务流程 > 提升员工体验 > 推动创新突破。结合两份数据,客户服务和企业内提效是智能体最确定的应用场景。

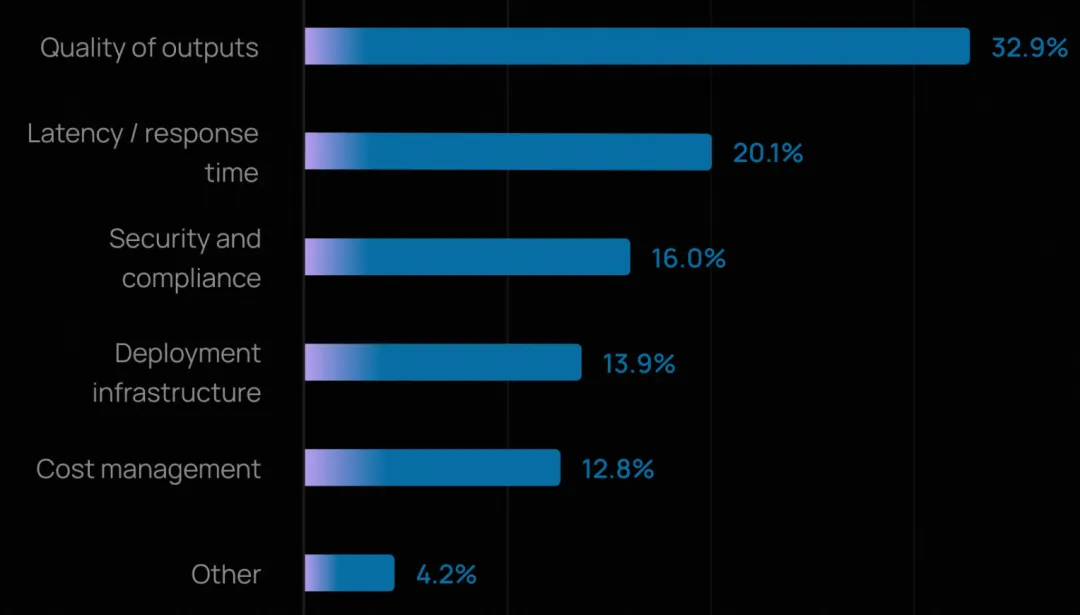
六、投产的最大障碍:质量、延迟与安全
质量仍是头号难题,与去年一致。今年有三分之一的受访者将其列为最大障碍。这里的“质量”涵盖准确性、相关性、一致性,以及智能体能否保持恰当语气并遵守品牌或政策规范。
延迟成为第二大挑战(20%)。随着智能体进入客户服务、代码生成等面向客户的场景,响应速度已成为用户体验的关键。这也反映了团队在质量与速度之间的权衡:能力更强、步骤更多的智能体虽能产出更高质量结果,但响应往往更慢。
成本作为担忧因素的提及率低于往年。模型价格下降和效率提升似乎已将组织的关注点从“花费多少”转向“如何让智能体又快又好”。
《AI 原生应用架构白皮书》侧重于技术层面的挑战进行调研:长回话状态管理 > 算力资源调度 > 数据梳理链路 > 异步通信需求,和质量、延迟、成本有所呼应。

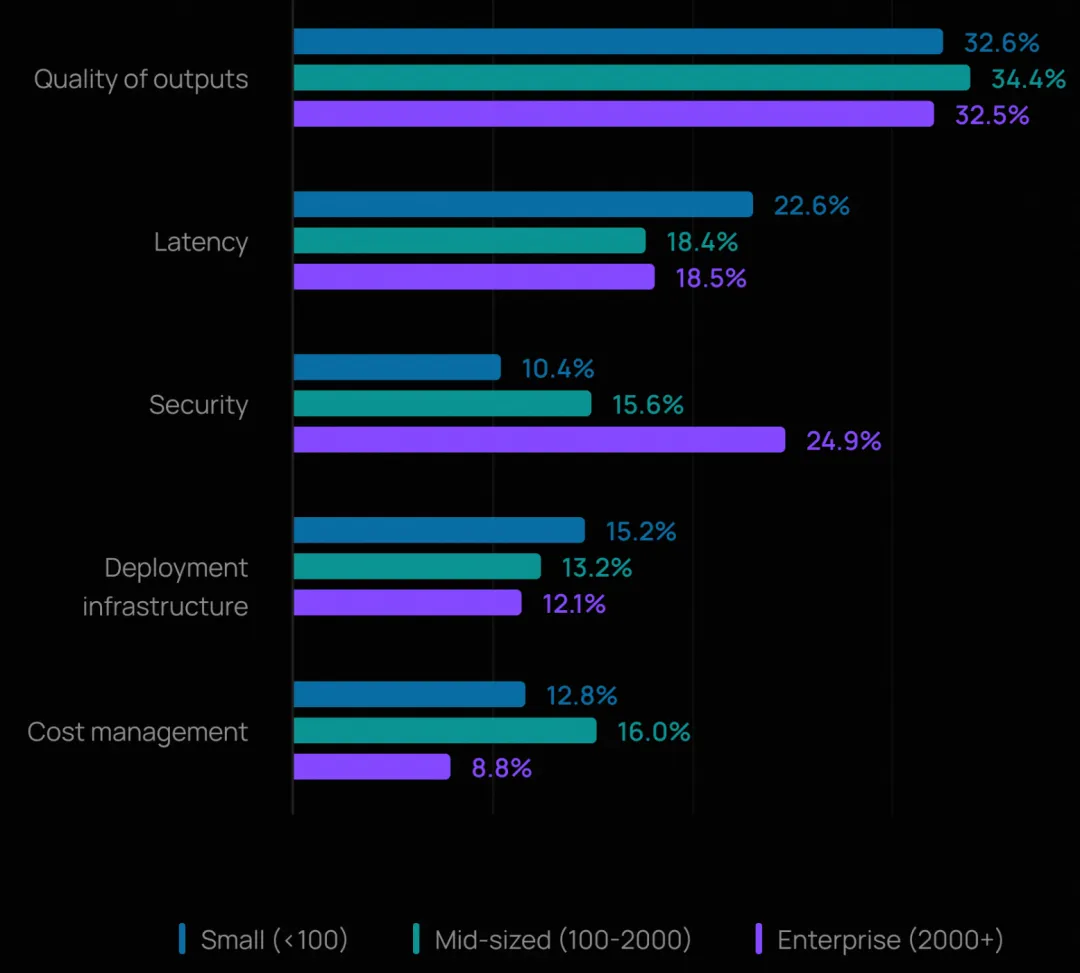
规模带来的新挑战
在 2,000 人以上的大型企业中,安全跃升为第二大障碍(24.9%),超过了延迟。这反映出大型组织对数据合规、权限控制和审计追踪的更高要求。
在万人以上企业中,开放式回答指出,幻觉和输出一致性是确保智能体质量的最大挑战。许多人还提到,在大规模场景下进行上下文工程和管理上下文仍十分困难。
《AI 原生应用架构白皮书》中提供了上下文工程和 AI 安全的一些初步探索。其中,上下文工程是技术难点,安全则依赖组织的体系化设计。


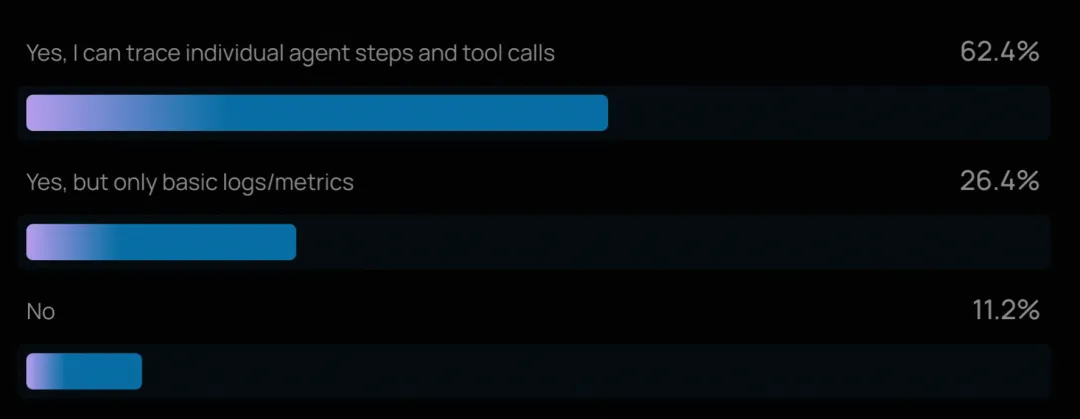
七、智能体可观测性:已成为行业标配
对多步推理链和工具调用进行追踪的能力,如今已是智能体工程的“基本要求”。89% 的组织已为其智能体实施了某种形式的可观测性,其中 62% 具备详细追踪能力,可检查智能体的每一步操作和工具调用。
在已上线智能体的团队中,这一比例更高,94% 拥有某种可观测性,71.5%具备完整追踪能力。这揭示了一个基本事实:若无法看清智能体如何推理和行动,团队就无法可靠地调试故障、优化性能,也无法赢得内外部利益相关者的信任。
《AI 原生应用架构白皮书》:调研了可观测的主流应用场景。

同时,《AI 原生应用架构白皮书》提供了相关的理论和实践。解决以上痛点的关键能力是:端到端的全链路跟踪、全栈观测、自动化评估。

八、智能体评估与测试:仍在追赶
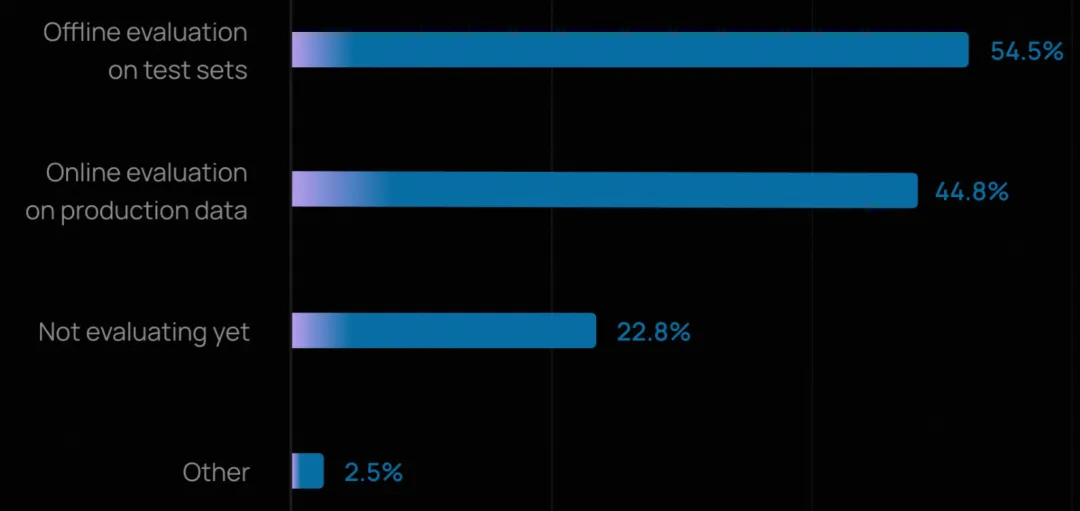
尽管可观测性已广泛普及,但智能体评估(evals)的采用仍在追赶中。略超一半的组织(52.4%)报告会在测试集上运行离线评估,表明许多团队已意识到在部署前捕捉回归和验证行为的重要性。
在线评估(online evals)的采用率较低(37.3%),但正在快速增长,因为团队开始监控智能体在真实世界中的表现。
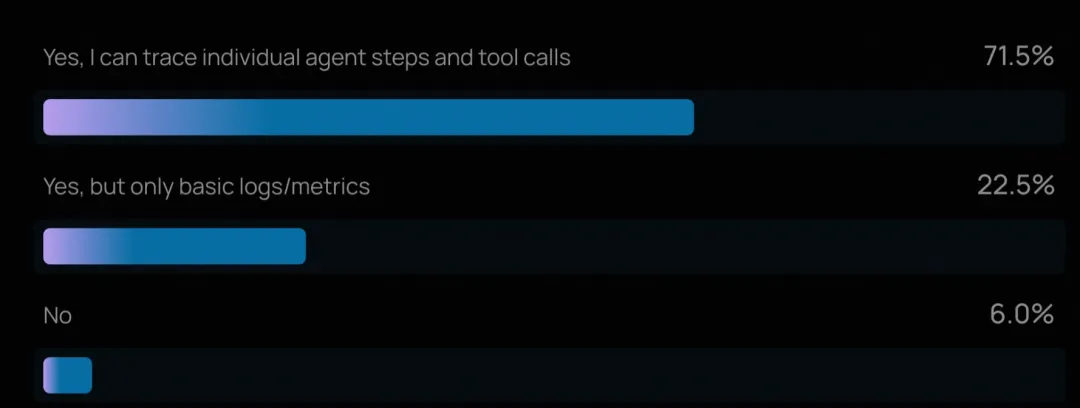
对于已上线智能体的团队,评估实践明显更成熟:“不评估”的比例从 29.5% 降至 22.8%,而进行在线评估的比例升至 44.8%。这表明一旦智能体面对真实用户,团队就必须依赖生产数据实时发现问题。
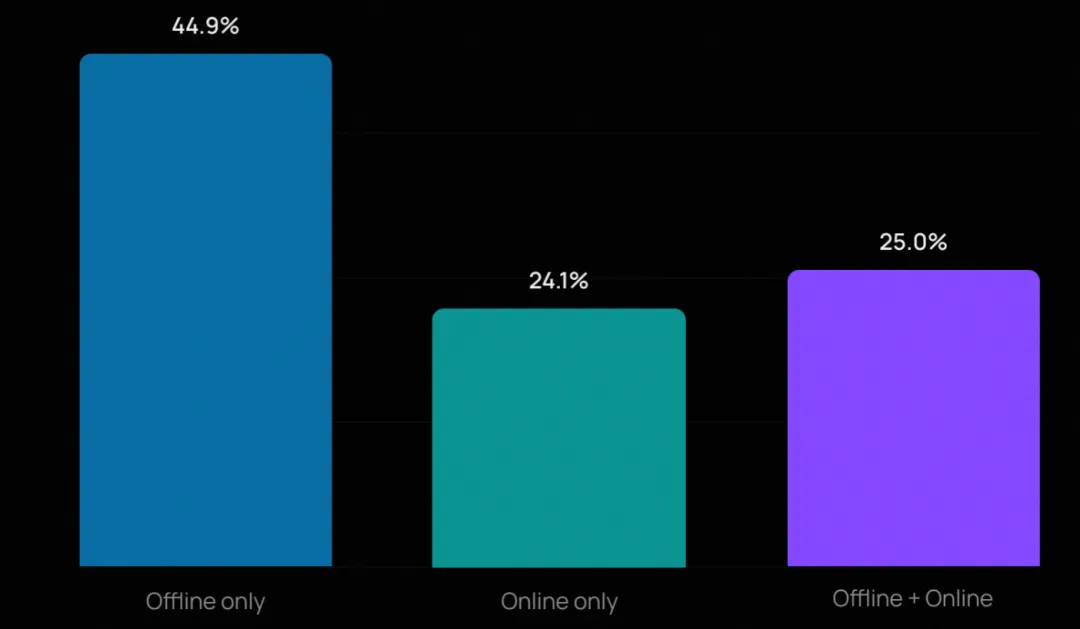
大多数团队仍从离线评估入手(因其门槛较低、设置更清晰),但许多正在叠加多种方法。在开展评估的组织中,近四分之一同时使用离线和在线评估。
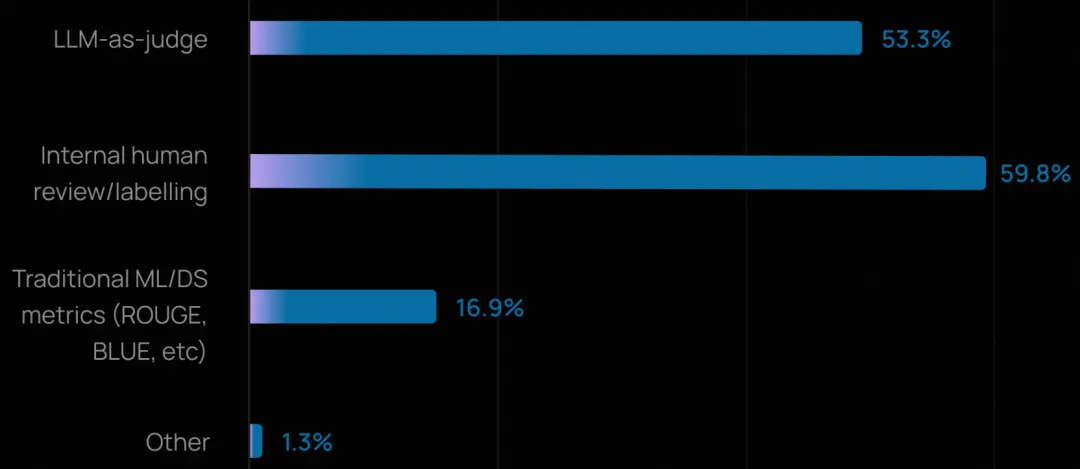
这些团队通常结合人工评审与自动化方法:用 LLM-as-Judge 实现广度覆盖,用人工审核处理深度判断。
总体而言,人工评审(59.8%)在高风险或需细腻判断的场景中仍不可或缺,而 LLM-as-Judge(53.3%)则被越来越多地用于规模化评估质量、事实准确性和合规性。
相比之下,传统的机器学习指标(如 ROUGE、BLEU)采用率很低,在开放式智能体交互中,往往存在多个有效答案,这些指标并不适用。
《AI 原生应用架构白皮书》也认为传统的机器学习指标(如 ROUGE、BLEU),存在较高的局限性。

更流行的是 LLM-as-Judge 范式,并提供了利用在线数据,实现自动化评估的实践框架。

九、模型与工具生态:开放、多元、务实
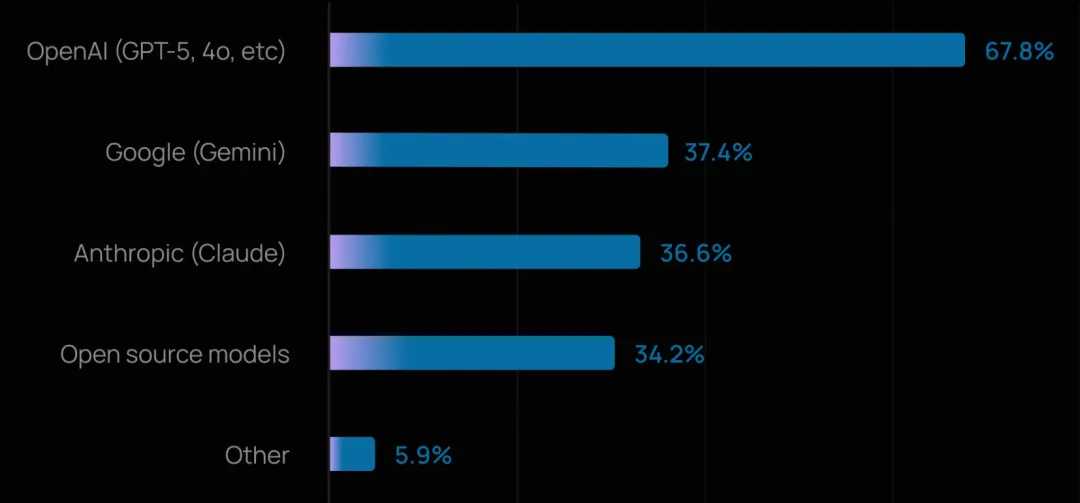
OpenAI 模型占据主导,但很少有团队押注单一供应商。超过三分之二的组织使用 OpenAI 的 GPT 系列模型,但超过四分之三(75%+)在生产或开发中使用多个模型。
团队越来越倾向于根据任务复杂度、成本和延迟等因素,将不同任务路由给不同模型,而非陷入平台锁定。
《AI 原生应用架构白皮书》中提到多模型策略是常态,通过 AI 网关可以高效、安全、量化管理模型供应和 Token 的消耗。
尽管商业 API 使用便捷,但自托管模型仍是重要策略。约三分之一的组织投入资源建设自有基础设施以部署开源模型。这可能是出于高用量下的成本优化、数据驻留/主权要求,或特定行业的监管约束。
同时,微调仍未普及。57% 的组织未进行任何微调,而是依赖基础模型结合提示工程和检索增强生成。由于微调需要大量投入(数据收集、标注、训练基础设施和持续维护),目前主要用于高影响力或高度专业化的场景。