
Claw Team 在 SRE 场景下的实践
作者:隐寒
从搜索指数看,个人养虾已经降温了,但不会消失,AI 的普及是一个循环向上的过程,不同人群之间会存在较大的温差。
事实上,Claw 已经成为不少个人或团队每天调用模型不可替代的入口,尤其是在一些线上巡检、定时发布的周期性任务上,以及一些团队协作的场景,非常适合多线程工作的人士。
另一边,有了个人养虾的背书,企业养虾开始进入决策期,评估通过企业采购行为设计虾场的应用场景和短中长期的目标,甚至有企业已经将此作为业务创新的牵引力。
以下分享一个我们在 SRE 场景下 Agent Team 的协作实践。
一、HiClaw 是什么
HiClaw 是一个面向企业的分布式多 Agent 运行平台,核心定位是让多个 Agent 在一个受控、可审计的环境中协同工作,人类全程可见、可介入。
与常见的单进程个人 AI 助手不同,HiClaw 自己不实现 Agent 逻辑,而是编排和管理多个 Agent 容器(Manager 和众多 Workers),这些 Agent 可以运行 OpenClaw 或 CoPaw 作为智能内核,后续还将支持 NanoClaw、ZeroClaw,甚至通过 CLI 方式接入企业自建 Agent。
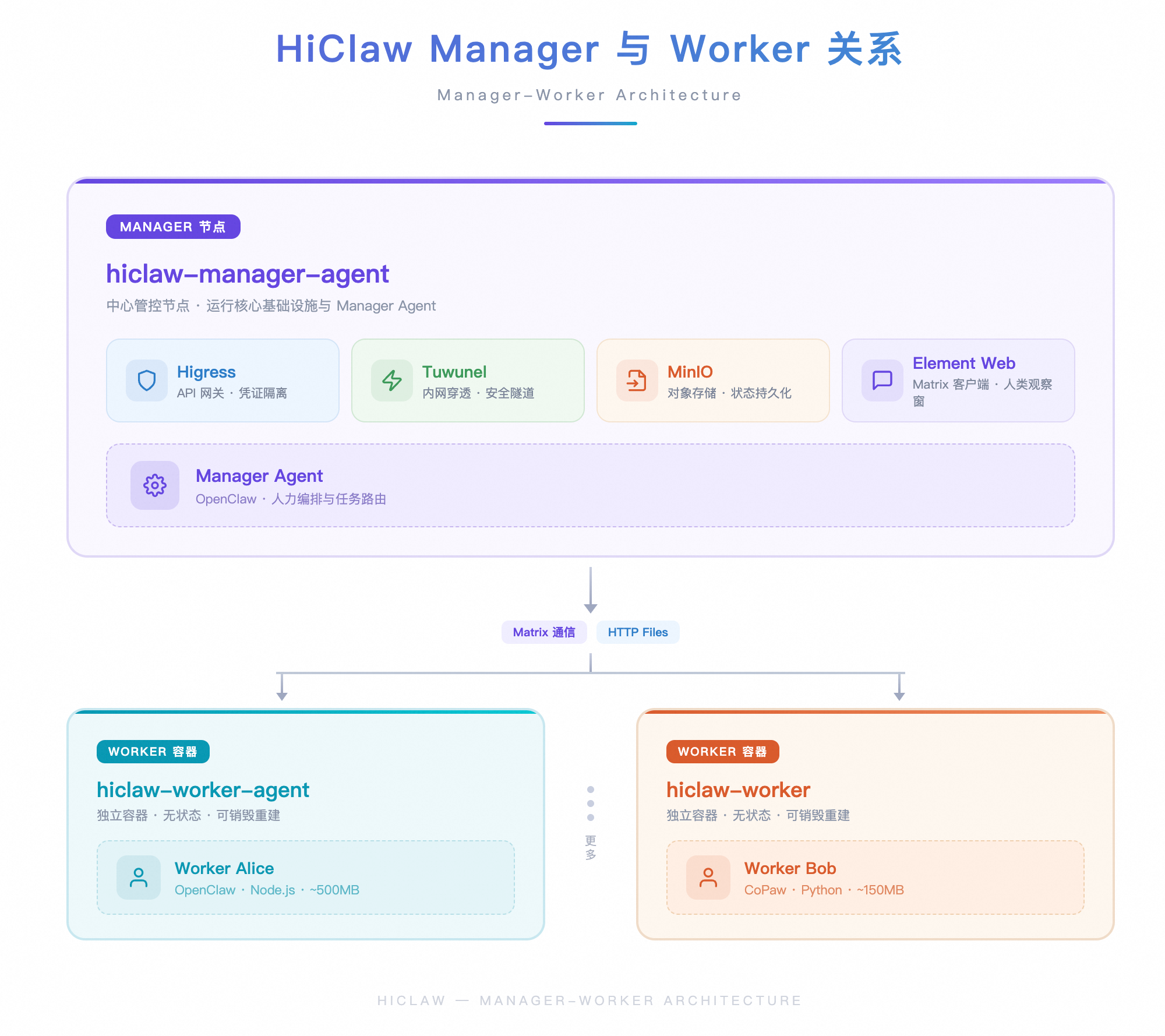
官方网站:https://hiclaw.io/
“泰山”是我们团队支持阿里云上的云原生产品的 SRE 系统。我们将在此系统上的隔离环境里,部署一套HiClaw,并应用于我们的运维场景。
二、构建 HiClaw 组织
HiClaw 初始化之后的状态
- 唯一的真人账号:
admin。通过对话使唤manager干活儿的权利。 - 唯一的数字人:
manager。具备操作操作 HiClaw 所有资源的权限,所有执行都需要通过 Manager;manager 本身就是一个 OpenClaw,内置任务与项目管理、系统管理、worker 管理等 Skills。Manager 默认是 OpenClaw 内核,未来会支持其他智能内核。
组建 Human 团队
与 manager 对话创建 Human 团队
任务:组建一个SRE团队,用于SRE(运维和测试)日常事务的沟通,并创建一个团队管家数字人叫做(sre-bot)团队组成:团队中包含一个团队管家和n个真人用户- 团队管家:是一个worker数字人,负责任务分解、成员协调、进度同步,唯一对接 Manager- 真人用户:都用于 @mention 团队管家的权利,让团队管家做事情的权利。- 真人账号参考附件来建立,登录账号为工号,名字为可见姓名,密码随机(账户密码请写入到文件中,我需要Matrix中下载)
权限要求:- 团队管家数字人,响应团队中所有真人账户派发的任务- manager不响应除了admin之外的真人用户下发指令之后,Manager 做了这么几件事情
- 提取 xlsx 文件中的用户名和工号创建 Matrix 账号
- 创建 SRE 数字人管家 sre-bot(选择 CoPaw 作为智能内核)
- 创建 SRE 团队
- 将 sre-bot 拉入到群中,并邀请 SRE 同事到群中
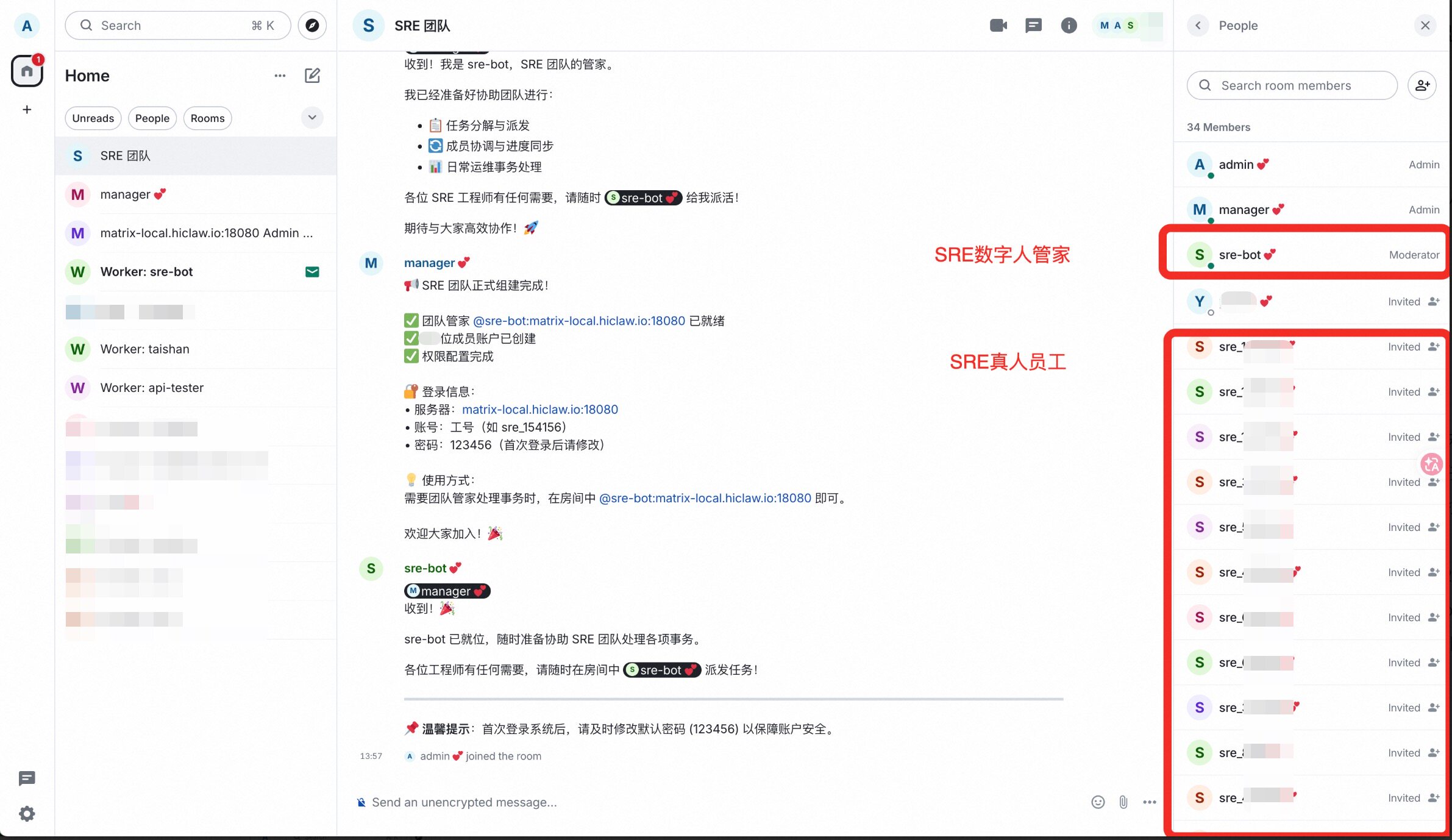
以上界面是 HiClaw 内置的的 Matrix 客户端 Element,默认是英文界面,可以改为中文界面。此外,也可以按照 OpenClaw 原生的方式接入钉钉、Discord、飞书等。
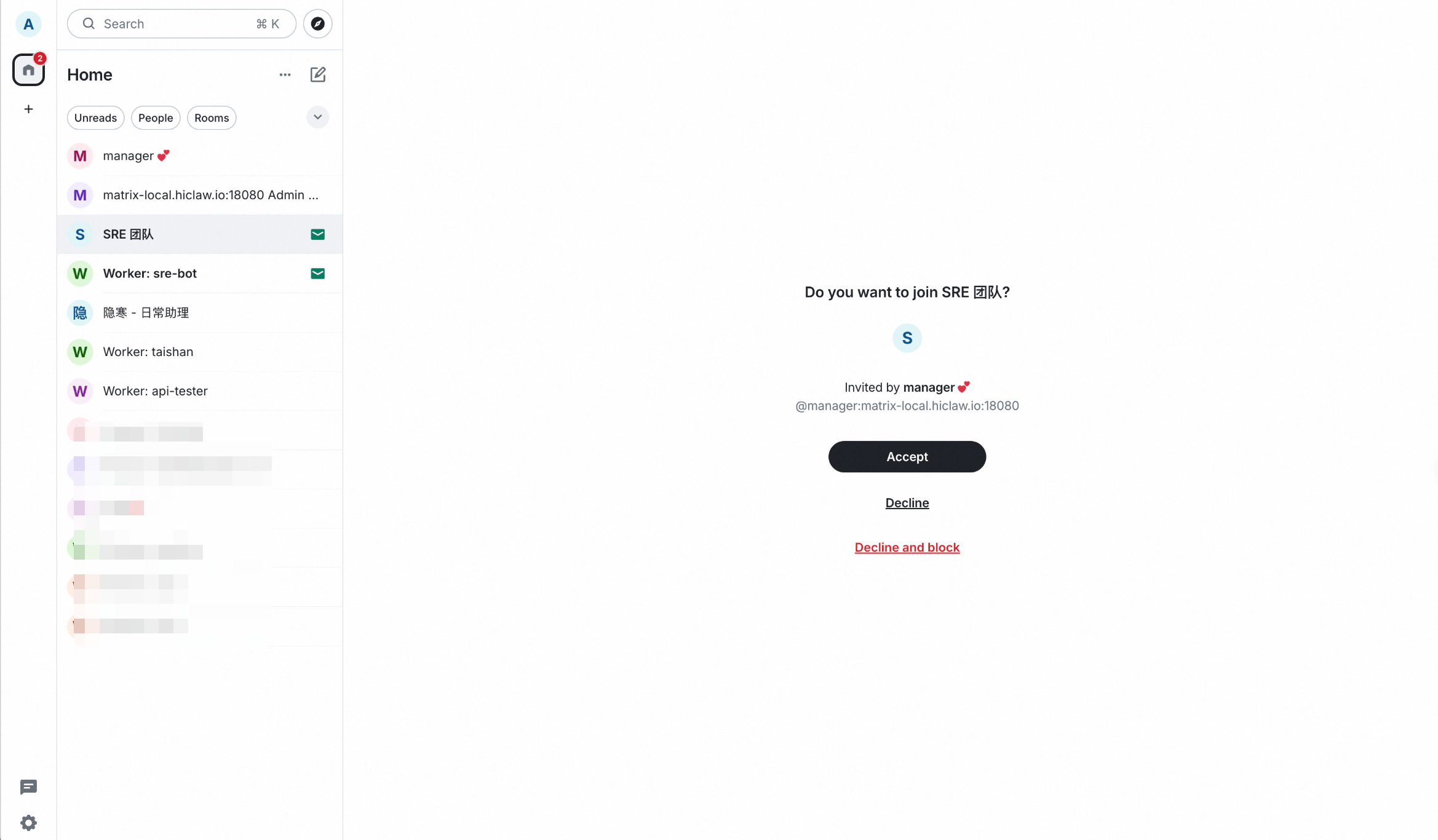
Manager 只是邀请了真人员工,真人员工需要登录到系统并接受邀请才代表真正进入了。接受邀请的界面如下。
数字人 Bot 职责设计
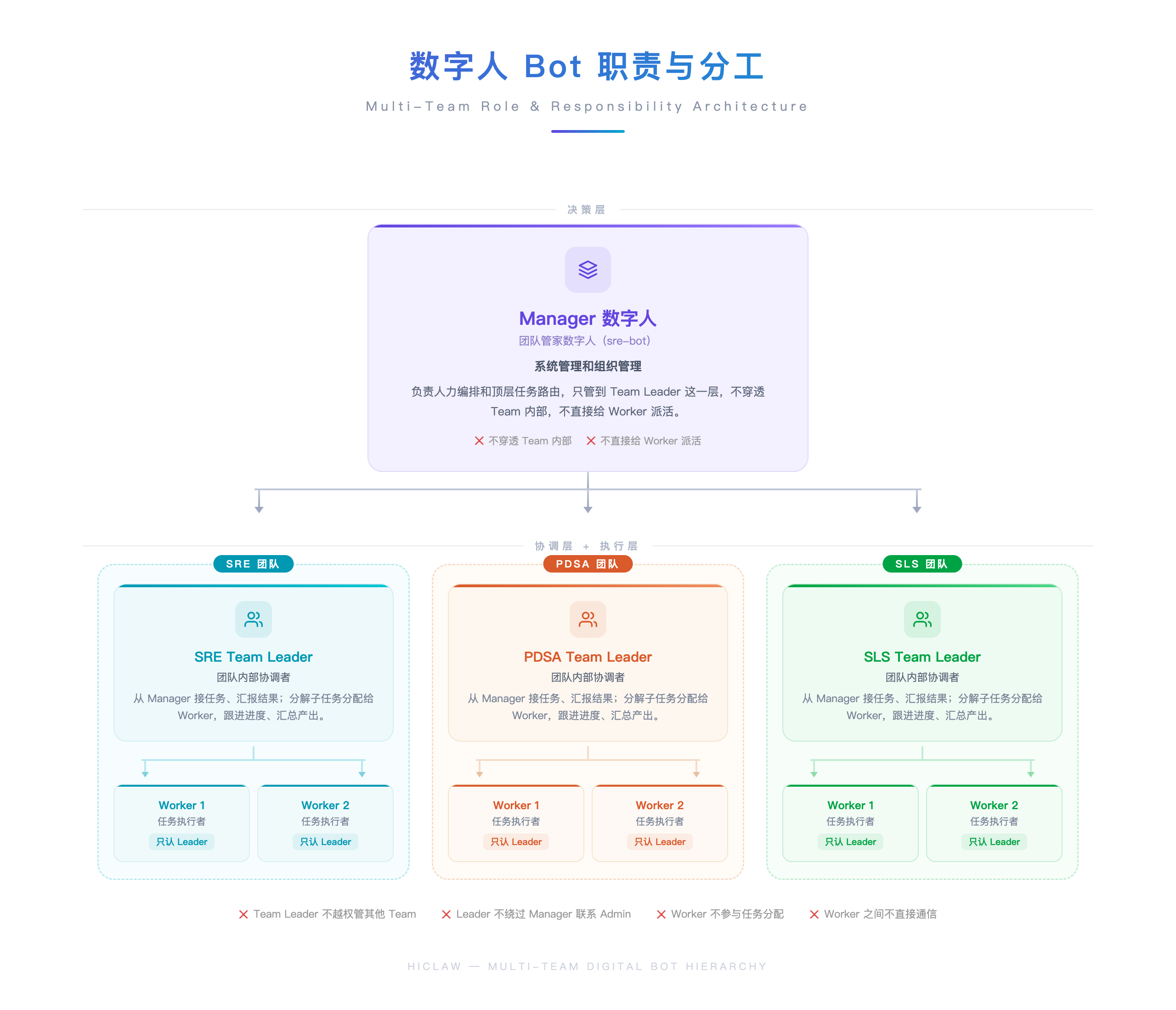
Human (Admin) └─ Manager Agent (唯一入口) ├─ Worker A (OpenClaw/CoPaw) ├─ Worker B └─ Worker C默认情况下,所有任务必须经由 Manager 分配,所有真人用户必须与 Manager 对话,这在企业场景中存在瓶颈:
- Manager 成为单点瓶颈,所有指令都需经过它
- Worker 之间无法自组织协调
- 无法映射企业真实团队结构
为了解决这个问题,引入了”团队管家“数字人
Human (Admin / Human Users) └─ Manager Agent (系统管理 + 组织管理) ├─ Team A │ └─ 团队管家数字 A (Team Leader,任务调度) ├─ Team B │ └─ 团队管家数字人 B (Team Leader, 任务调度) │ └─ Worker Pool (共享资源池, 按授权分配) ├─ Worker 1 ──── 授权 → Team A, Team B ├─ Worker 2 ──── 授权 → Team A ├─ Worker 3 ──── 授权 → Team B └─ Worker 4 ──── 独立 Worker (不属于任何 Team)数字人 Bot 的职责和分工如下:
| 类型 | 职责 | 描述 |
|---|---|---|
| Manager 数字人 | 系统管理和组织管理 | 负责人力编排和顶层任务路由,只管到 Team Leader 这一层,不穿透 Team 内部,不直接给 Worker 派活。 |
| 团队管家数字人(sre-bot) Team Leader | 团队内部协调者 | 对上从 Manager 接任务、汇报结果,对下将任务分解为子任务分配给 Worker、跟进进度、汇总产出。不越权管其他 Team,不绕过 Manager 联系 Admin。 |
| Worker 数字人 | 任务执行者 | 只认 Team Leader,专注执行单个子任务,完成后向 Leader 汇报。不参与任务分配,不与其他 Worker 直接通信。 |
Manager管”系统和组织”,Leader 管”任务调度”,Worker 管”做出来”。拆分之后的好处:
- Manager 的 SOUL 可以做得很轻(管理类指令集),Team Leader 的 SOUL 可以做得很专(领域任务调度)。各自的 prompt 更聚焦,AI 决策质量更高。
- Admin/Human 的任务请求直接到 Team Leader,不需要绕道 Manager。
- 不同 Team Leader 可以有不同的领域专长(前端团队、后端团队、测试团队),按业务线组织。
- Team 内部的调度逻辑可以独立演进,改一个 Team 的策略不影响其他 Team。
- Manager 挂了只影响系统管理操作(创建/销毁 Worker),已有的 Team 可以继续正常工作。
Human 和数字人权限设计
Admin 管平台,团队负责人管团队,团队员工用团队
- 三种数字人:Manager 数字人,团队管家数字人,Worker 数字人
- 三种 Human 角色:Admin、团队负责人、团队员工

| 维度 | Admin(系统管理员) | 团队负责人 | 团队员工 |
|---|---|---|---|
| 定位 | 管平台 | 管团队 | 用团队 |
| Manager | ✅ 直接操作 | ❌ | ❌ |
| 创建/销毁 Team | ✅ | ❌ | ❌ |
| 创建 Worker | ✅ 全局 | ✅ 自己 Team | ❌ |
| 创建 Human 账号并拉入团队 | ✅ 全局 | ✅ 自己 Team | ❌ |
| 管理团队管家的 SOUL/Skills | ✅ 所有 Team | ✅ 自己 Team | ❌ |
| 管理 Worker 的 SOUL/Skills | ✅ 所有 | ✅ 自己 Team 的 | ❌ |
| 与团队管家对话 | ✅ 所有 | ✅ 自己 Team | ✅ 自己 Team |
| 与 Worker 对话 | ✅ 所有 | ✅ 自己 Team 的 | ✅ 自己 Team 的 |
| 创建 Case | ✅ 任意 | ✅ 自己 Team | ✅ 自己 Team |
admin 通过@sre-bot 设置团队负责人:
@sre-bot为团队管家;将隐寒设置为团队负责人,其他人为团队员工,相关的权限配置如下,你需要把下面信息写入到你的rule里面,并严格执行:
| 维度 | Admin(系统管理员) | 团队负责人 | 团队员工 || --- | --- | --- | --- || **定位** | 管平台 | 管团队 | 用团队 || **Manager** | ✅ 直接操作 | ❌ | ❌ || **创建/销毁 Team** | ✅ | ❌ | ❌ || **创建 Worker** | ✅ 全局 | ✅ 自己 Team | ❌ || **创建 Human 账号并拉入团队** | ✅ 全局 | ✅ 自己 Team | ❌ || **管理团队管家的 SOUL/Skills** | ✅ 所有 Team | ✅ 自己 Team | ❌ || **管理 Worker 的 SOUL/Skills** | ✅ 所有 | ✅ 自己 Team 的 | ❌ || **与团队管家对话** | ✅ 所有 | ✅ 自己 Team | ✅ 自己 Team || **与 Worker 对话** | ✅ 所有 | ✅ 自己 Team 的 | ✅ 自己 Team 的 || **创建 Case** | ✅ 任意 | ✅ 自己 Team | ✅ 自己 Team |
至此,群里的 Human 角色都可以 @sre-bot 来下发任务了,但是只有“团队负责人”可以更新 sre-bot 的技能和 soul:

配置好权限之后,如果 sre-bot 不响应,让 manager 重启下 sre-bot worker,否则虽然配置都对,依然不会生效。

创建 SRE Worker 数字人
泰山的 SRE 智能体设计如下:
| 数字人 | 领域 | 能力 | 涵盖 skill |
|---|---|---|---|
| 泰山 Knowledge Kit 数字人 | 知识领域 | 通过 knowledge-kit 命令将文档按指定 spec 转换为结构化知识 Markdown。 | knowledge-skill |
| 泰山 QA/E2E 数字人 | 测试域 | 根据用户提供的验收表(xlsx)、目标 URL 和 Cookies(或通过 Argo UI MCP 自动获取),自主生成 Agent 执行指南并不中断地完成全部功能点验收,最终输出含验收结果的验收表。 | agent-prod-e2e-testing |
| 泰山 QA/OpenAPI 数字人 | 测试域 | 自动为阿里云 Java SDK 产品接口生成测试用例,并自动提交代码、创建 Code Review。 | api-resource-classifier api-test-auto-submit api-test-generator |
| 泰山运维/泰山咨询和诊断数字人 | 运维域 | 云产品或者实例的咨询或者诊断专家。负责知识答疑,云产品 FAQ、实例诊断,故障诊断、最佳实践咨询等。查询实例的详情,K8s 资源等信息。 | taishan-instance-query taishan-ticket-skills |
| 泰山运维/K8s RCA 数字人 | 运维域 | Kubernetes 根因分析专家。当用户遇到 K8s 相关问题(Pod 异常如 Pending/CrashLoopBackOff/ImagePullBackOff/Terminating/Evicted、Deployment/StatefulSet/DaemonSet 状态异常、节点 NotReady、服务无法访问、kubectl 报错、容器/调度/网络/存储问题)时,立即使用此 skill。通过 SOP 驱动的方式,遵循「先规划、后执行」原则,使用 5 Whys 方法定位可行动、防复现的根因。 | k8s-rca-skills |
可能有人会问,为什么设置5个数字人,而不是让一个数字人去执行呢?我们先对两个方案做一个对比:
| 维度 | 专职数字人(方案 A) | 全能数字人(方案 B) |
|---|---|---|
| 推理深度 | ✅ 深:单一领域 SOP 完整执行 | ⚠️ 浅:多 Skill 竞争上下文资源 |
| 工具调用精准度 | ✅ 高:工具集小,意图明确 | ⚠️ 中:工具集大,选择歧义增加 |
| SOP 遵循度 | ✅ 高:RCA 的「先规划后执行」不受干扰 | ❌ 低:多 SOP 并存时易跳步或混用 |
| 并发处理能力 | ✅ 强:多任务可并行分配给不同数字人 | ❌ 弱:单实例串行,存在瓶颈 |
| 故障隔离 | ✅ 强:单个数字人异常不影响其他 | ❌ 弱:单点故障影响全部能力 |
| 跨能力协作 | ⚠️ 需要编排层协调 | ✅ 天然支持,无需切换 |
| 用户入口 | ⚠️ 需要用户选择正确的数字人 | ✅ 统一入口,用户无感知 |
| 维护成本 | ⚠️ 5 个独立配置,维护分散 | ✅ 1 个配置,集中管理 |
然后我们结合两个场景来看看两个方案的不同:
故障排查场景:生产环境 Pod CrashLoopBackOff
| 专职数字人(方案 A) | 全能数字人(方案 B) |
|---|---|
| 直接进入 RCA 数字人 | 需要意图识别:RCA 还是咨询诊断? |
| SOP 驱动:先规划分析路径 | 可能同时激活两个 Skill 的工具 |
| 5 Whys 逐层深挖:OOM → JVM 参数 → 资源限制配置错误 | 5 Whys 推理被诊断工具调用打断 |
| 输出可行动根因 + 防复现建议 | 结论可能停留在表层(重启 Pod) |
| ✅ 推理链完整,结论精准 | ⚠️ 推理深度不足,根因可能不准 |
新版发布场景:文档更新 + E2E 验收 + 故障排查
| 维度 | 专职数字人(方案 A) | 全能数字人(方案 B) |
|---|---|---|
| 推理深度 | Knowledge Kit → 更新文档知识库 | 单实例串行处理三个任务 |
| 工具调用精准度 | QA/E2E → 并行执行功能验收 | 文档转换 → E2E 验收 → 故障分析 |
| SOP 遵循度 | 验收失败 → 自动路由 RCA 数字人 | 上下文在三个任务间切换,易混淆 |
| 并发处理能力 | 三个任务可并行,总耗时最短 | 总耗时 = 三个任务之和 |
| 故障隔离 | ✅ 并行高效,职责清晰 | ⚠️ 串行低效,上下文污染风险 |
看到着,大家可能有一致的感受,Agent Team 需要花费较多的时间设计数字人的架构,依赖个人经验;从 ROI 角度看,适合周期性任务(一劳永逸)或者复杂、长程任务。
接下来,我们基于以上架构在 HiClaw 中构建所有 SRE Worker 数字人,并构建 Human 和所有人相关的权限;由于每个 Worker 数字人就是一个 Copaw/OpenClaw,因此相关的配置也非常简单:
新增5个 worker 数字人:
| 数字人 | 领域 | 能力 | 涵盖 skill || --- | --- | --- | --- || 泰山 Knowledge Kit | 知识领域 | 通过 knowledge-kit 命令将文档按指定 spec 转换为结构化知识 Markdown。 | knowledge-skill || 泰山 QA/E2E 数字人 | 测试域 | 根据用户提供的验收表(xlsx)、目标 URL 和 Cookies(或通过 Argo UI MCP 自动获取),自主生成 Agent 执行指南并不中断地完成全部功能点验收,最终输出含验收结果的验收表。 | agent-prod-e2e-testing || 泰山 QA/OpenAPI 数字人 | 测试域 | 自动为阿里云 Java SDK 产品接口生成测试用例,并自动提交代码、创建 Code Review。 | api-resource-classifier, api-test-auto-submit, api-test-generator || 泰山运维/泰山咨询和诊断数字人 | 运维域 | 查询实例的详情,k8s 资源等信息;云产品或者实例的咨询或者诊断专家,但是无法做k8s底层的根因诊断。OXS区产品(HSF (Configserver)、Diamond、Vipserver、MetaQ、SchedulerX2.0)的知识答疑,云产品 FAQ、实例诊断,故障诊断、最佳实践咨询等。 | taishan-instance-query, taishan-ticket-skills || 泰山运维/K8S RCA 数字人 | 运维域 | Kubernetes 根因分析和诊断专家,通过k8s clusteruuid、pod等信息来进行问题诊断。当用户遇到 K8s 相关问题(Pod 异常如 Pending/CrashLoopBackOff/ImagePullBackOff/Terminating/Evicted、Deployment/StatefulSet/DaemonSet 状态异常、节点 NotReady、服务无法访问、kubectl 报错、容器/调度/网络/存储问题)时,立即使用此 skill。通过 SOP 驱动的方式,遵循「先规划、后执行」原则,使用 5 Whys 方法定位可行动、防复现的根因。 | k8s-rca-skills |紧接着,admin 让 Manager 赋予 sre-bot 相关权限
@manager: 请赋予 sre-bot 创建worker和管理worker的权限,并可以自由分配任务给worker但是 sre-bot 并不具备创建 worker 的 skill 能力,最终在 Manager 的协作完成任务

让 sre-bot 将数字人加入群聊
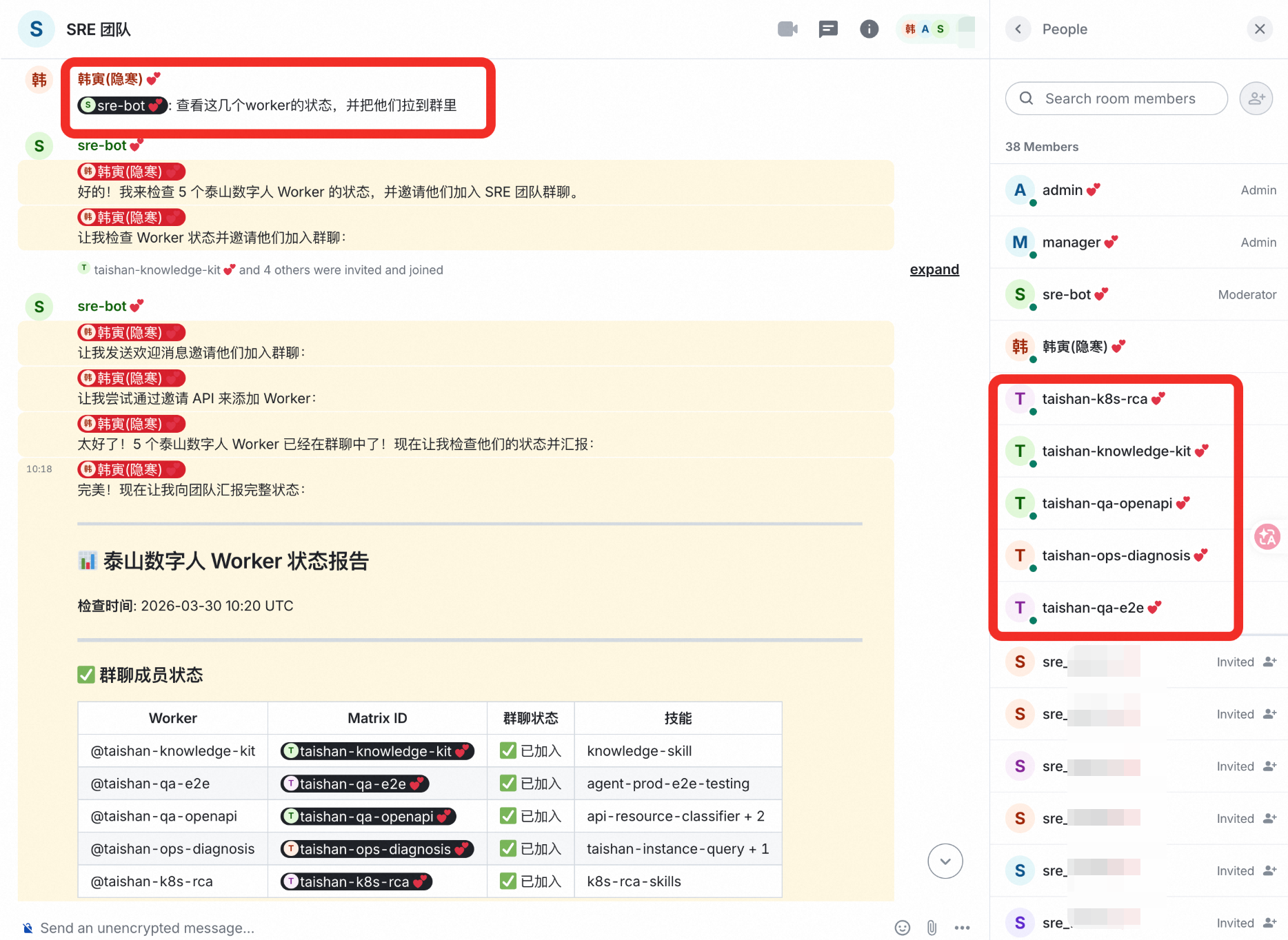
至此,完成 SRE 的 HiClaw 组织构建,下面开始体验一把。
三、HiClaw 多智能体的运维场景
我们设定了阿里云 MSE 微服务引擎这款产品,网关变配失败的问题排查场景。
角色: L1/L2 客服,产研
场景:在 SPE 环境中,预先购买一个 MSE 云原生网关实例,发现 pod 起不来
真人:发起任务
SRE 团队负责人通过 Team Leader(SI Put)下发诊断指令,触发多智能体协同流程,系统自动创建独立任务空间,隔离上下文,避免干扰其他任务。

SRE 团队管家数字人:分解任务
Team Leader 基于预设 SOP,将“K8s 实例调度失败”问题拆解为三阶段任务:实例状态核查 → 资源瓶颈诊断 → K8s 维度根因分析,并按顺序调度对应 Worker。

SRE 团队管家数字人:拉项目群&下发任务
团队管家数字人在群里,把每个人任务下发给对应的数字人(泰山诊断数字人和 K8s RCA 数字人)。
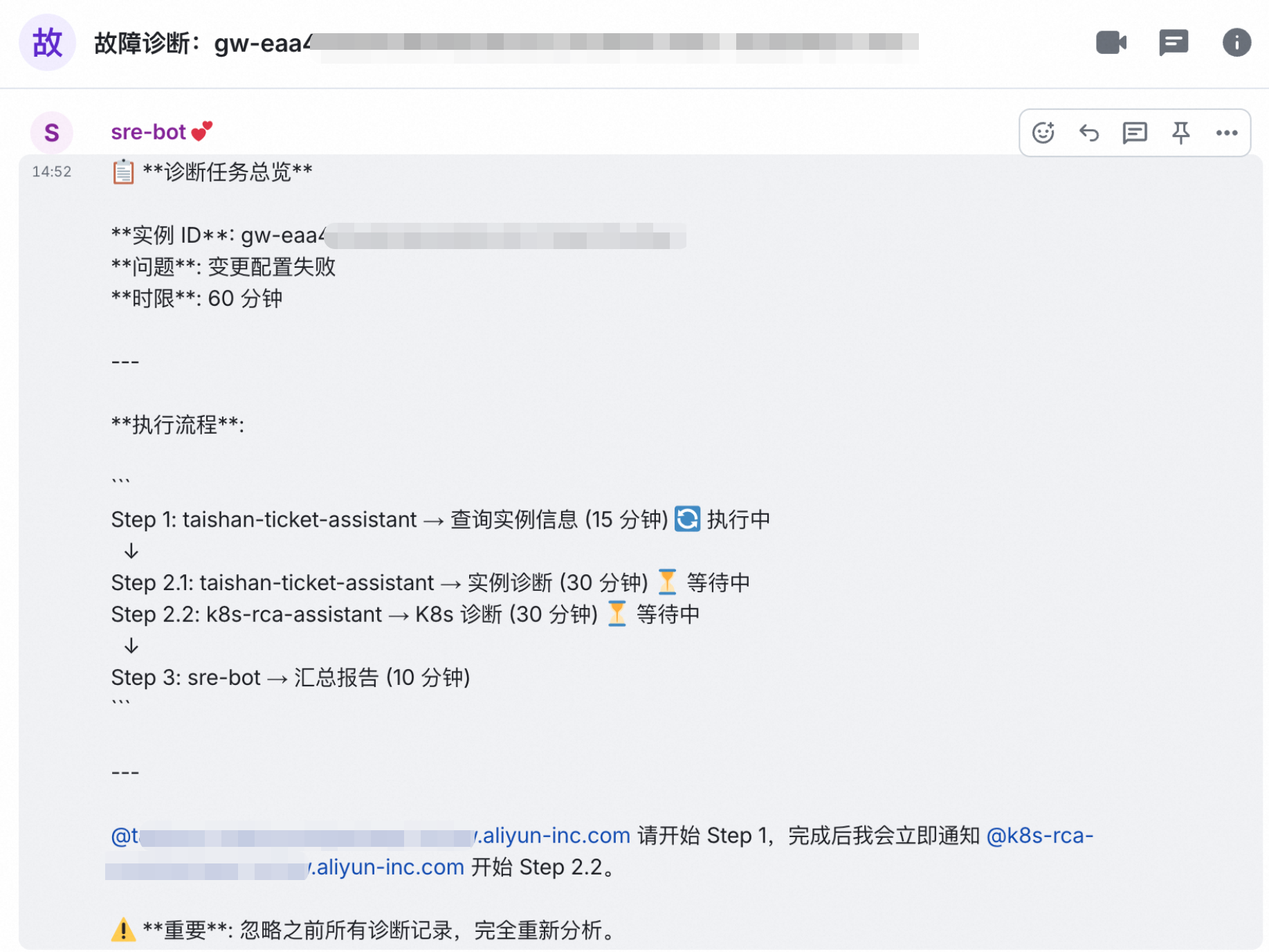
泰山诊断数字人:实例基础信息获取和实例诊断
泰山诊断数字人调用泰山系统接口,查询目标实例的运行状态,确认其中一个 pod 的状态其处于“Pending”,调度失败。
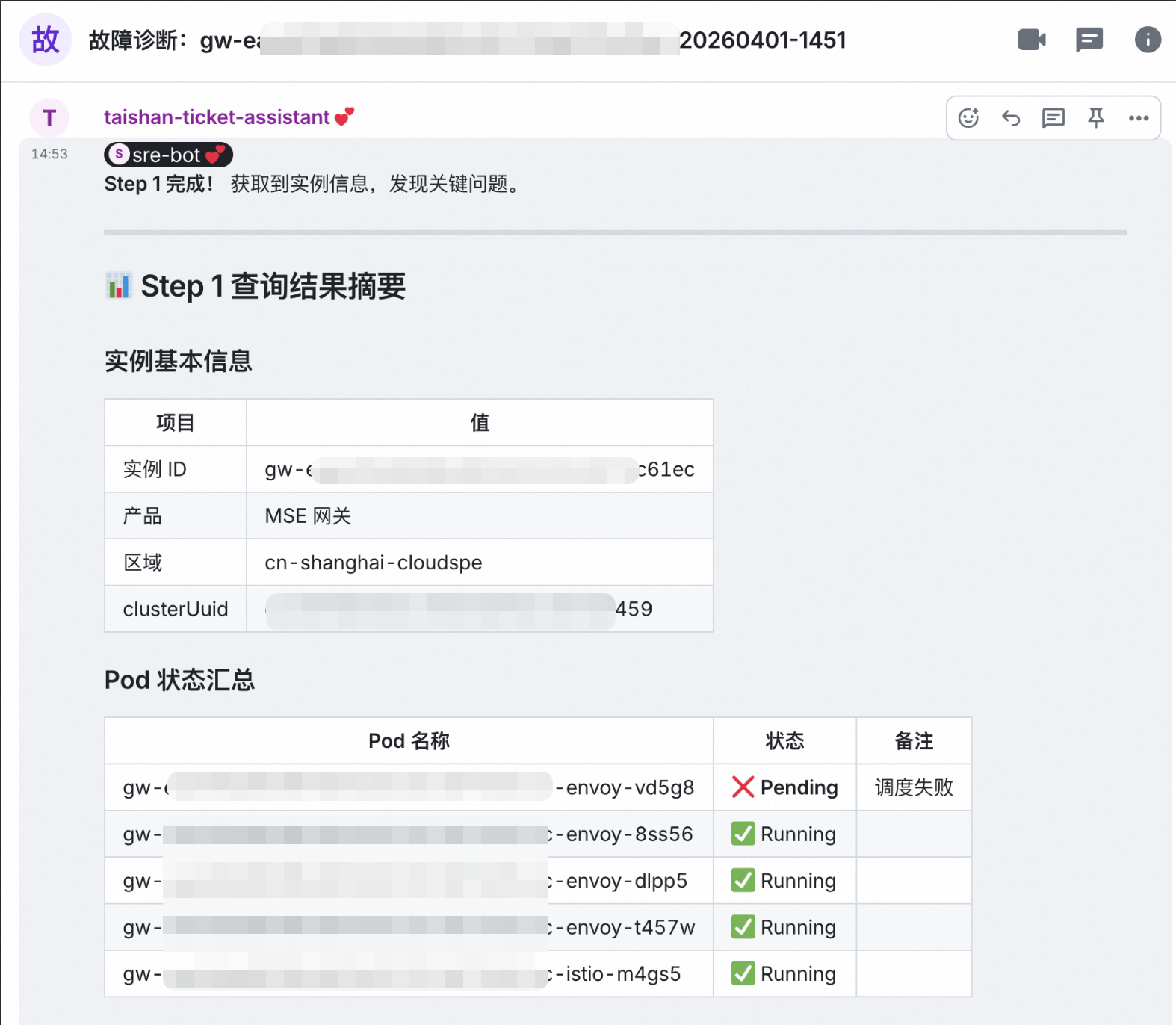
泰山诊断数字人:实例诊断
泰山诊断数字人实例诊断报告,调度失败日志指向“Insufficient CPU/Memory”,初步锁定为节点资源不足,且 PVC 无法绑定 PV。
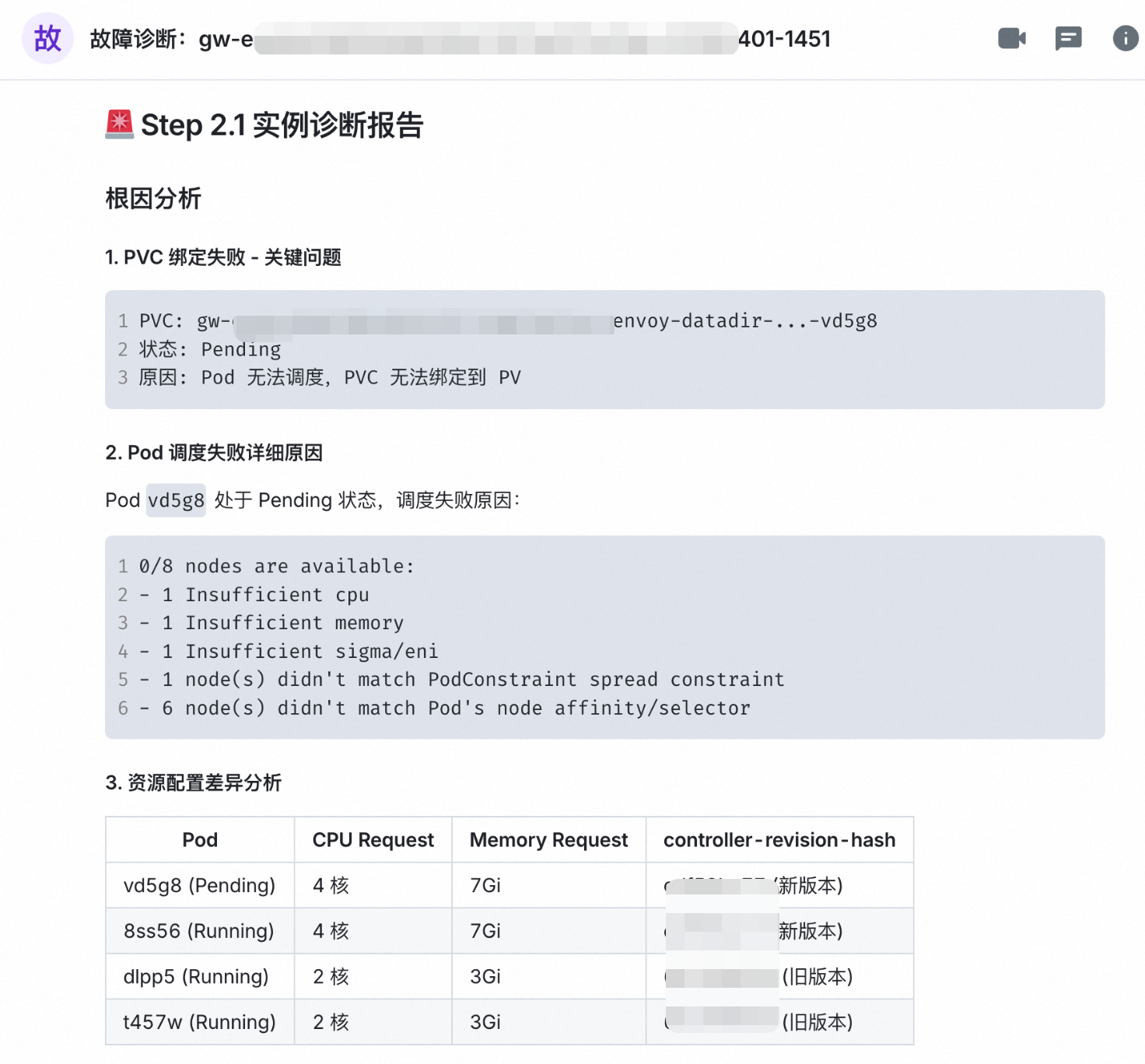
K8s RCA 数字人:K8s 诊断
K8S RC Agent 启动标准诊断流程,发现异常节点(work-a)的 CPU 使用率持续>95%,内存可用量低于5%,确认为节点池容量瓶颈,但无法定位具体 Pod 或服务。

按 SOP 依次排查:Pod 调度策略、节点亲和性、Taints/Tolerations、Eviction 阈值,最终确认因节点资源枯竭,K8s 调度器拒绝了新 Pod 的调度请求。
![]()
SRE 团队管家数字人:汇总结果
Team Leader 整合三阶段结果,生成结构化报告,明确根因为“work-a 节点池资源不足导致调度失败”,并推荐执行“扩容 work-a 节点池+2节点”操作,附带资源预估与影响评估。
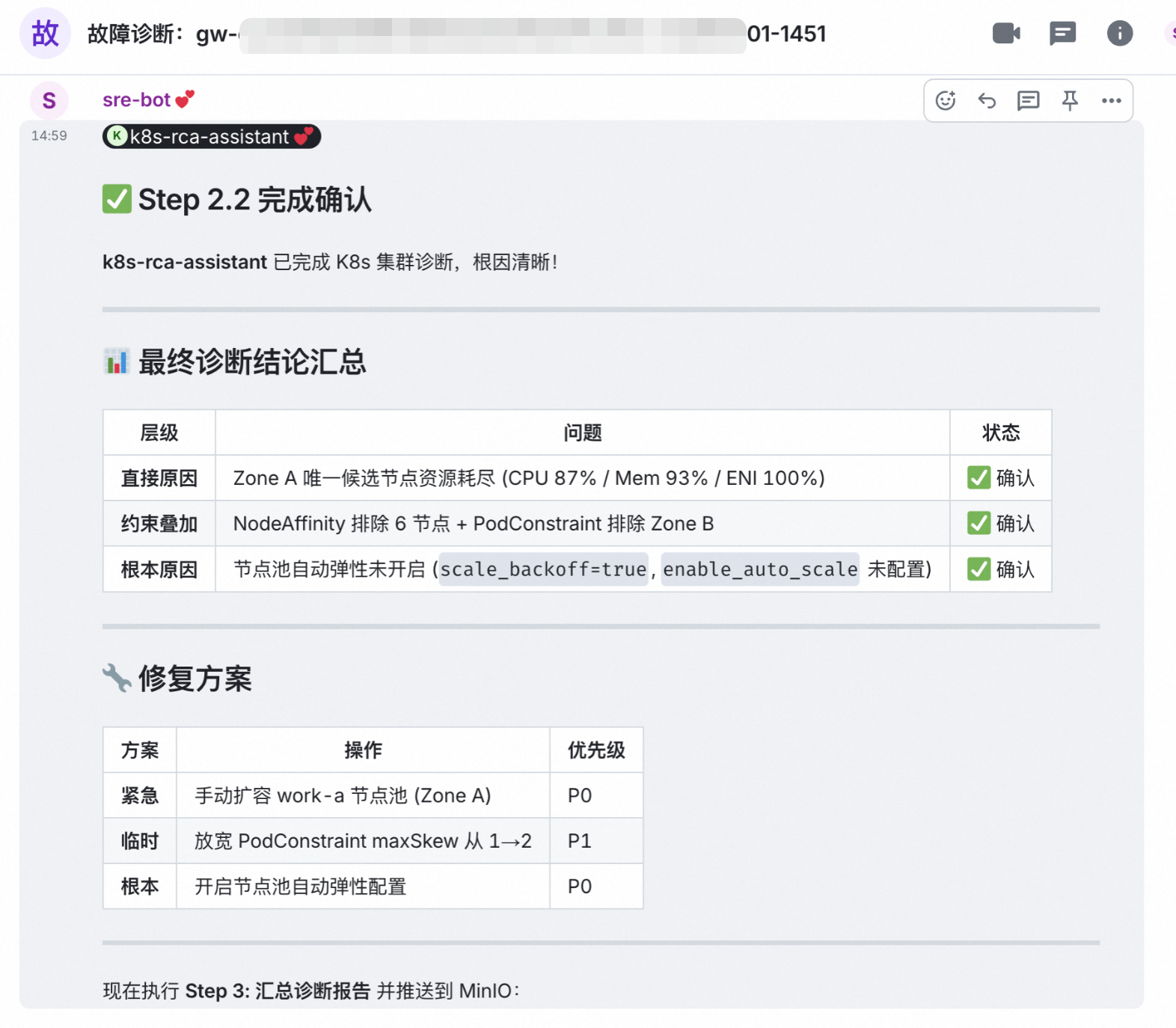
整个流程无需人工干预,智能体串行协作完成端到端诊断,输出可直接交付运维团队的标准化操作方案,实现从问题发现到修复建议的自动化闭环。
四、总结
个人养虾的热度回落,恰恰说明 AI 智能体正在从尝鲜走向日常。Claw 已经成为许多人和团队每天离不开的工具入口,而企业端也开始认真评估规模化建设虾场的路径。我们在 SRE 场景的实践验证了一个核心判断:智能体的价值不在于单体有多强,而在于能否用平台化的方式让它们协同生长。
从实际收益看,HiClaw 带来的变化是多维度的:
- 效率层面,大量重复性的巡检、发布、故障响应工作由 Agent 接管,人工介入频次显著下降,部分周期性任务实现了从”人盯”到”人查”的转变。
- 协作层面,SOUL 和 Skills 作为可复用资产沉淀下来,跨团队共享而非重复建设,新智能体的上线周期从开发级缩短到配置级。
- 更深层的价值在于业务创新——当构建智能体的门槛降低到业务团队可以自主完成,探索新场景的成本也随之降低,AI 不再是平台团队的专属工具,而成为每个团队都能调用的生产力。
HiClaw 让团队把重心从写代码转向写配置,把核心资产沉淀为 SOUL 与 Skills,把复杂问题交给 Team 而非单个 Agent——不是造更强的智能体,而是造能长出智能体的土壤。这条路,无论个人还是企业,逻辑是相通的。